|
引言
在Oracle数据库的浩瀚世界里,数据本身固然重要,但如何高效地组织、访问和管理这些数据,才是发挥其强大威力的关键。这一切都离不开数据库对象。无论是初入行的DBA还是后端开发人员,熟练掌握Oracle常用对象的创建与管理都是一项核心技能。
本文将带您系统地了解Oracle 11g中几种最常用的数据库对象,包括表、视图、序列、索引和同义词。我们将通过清晰的语法示例和实用的管理技巧,助您夯实基础,提升数据库操作能力。
一、表(Table):数据的基石
表是数据库中存储数据的基本单位,由行和列组成。设计良好的表结构是高效数据库系统的前提。
1. 创建表
使用 CREATE TABLE 语句,你需要定义列名、数据类型和约束。
CREATE TABLE employees (
employee_id NUMBER(6) PRIMARY KEY,
first_name VARCHAR2(20),
last_name VARCHAR2(25) NOT NULL,
email VARCHAR2(25) NOT NULL UNIQUE,
hire_date DATE DEFAULT SYSDATE NOT NULL,
salary NUMBER(8,2),
department_id NUMBER(4),
-- 定义外键约束,关联到部门表
CONSTRAINT fk_dept_id
FOREIGN KEY (department_id)
REFERENCES departments(department_id)
);关键点:
数据类型: NUMBER, VARCHAR2, DATE, CLOB, BLOB 等。 约束: PRIMARY KEY, FOREIGN KEY, NOT NULL, UNIQUE, CHECK。约束保证了数据的完整性和一致性。
2. 管理表
-- 添加新列
ALTER TABLE employees ADD (phone_number VARCHAR2(15));
-- 修改列数据类型
ALTER TABLE employees MODIFY (salary NUMBER(9,2));
-- 删除列
ALTER TABLE employees DROP COLUMN phone_number;
-- 添加约束
ALTER TABLE employees ADD CONSTRAINT chk_salary CHECK (salary > 0); DROP TABLE employees;
-- 谨慎使用!会删除表结构和所有数据。
DROP TABLE employees CASCADE CONSTRAINTS;
-- 同时删除与之相关的引用完整性约束 RENAME employees TO emp_backup;
- 截断表(TRUNCATE TABLE): 快速删除表中所有数据,不可回滚,并释放表空间。
TRUNCATE TABLE emp_backup;
二、视图(View):虚拟的逻辑窗口
视图是基于一个或多个表的查询结果集。它本身不存储数据,像一个预定义的查询窗口,简化了复杂查询,增强了数据安全性。
1. 创建视图
CREATE OR REPLACE VIEW vw_emp_dept AS
SELECT e.employee_id,
e.first_name || ' ' || e.last_name AS full_name,
e.salary,
d.department_name
FROM employees e
JOIN departments d ON e.department_id = d.department_id
WHERE e.salary > 10000;
2. 管理视图
SELECT * FROM vw_emp_dept; 优点:
简化操作: 将复杂的多表查询封装成一个简单的视图。 安全性: 可以只暴露视图中的特定列给用户,隐藏敏感数据。 逻辑独立性: 即使底层表结构发生变化,只需修改视图定义,而不影响应用程序。
三、序列(Sequence):自动编号发生器
序列是一个数据库对象,用于生成唯一的、连续的整数编号,通常为主键字段提供值。
1. 创建序列
CREATE SEQUENCE seq_emp_id
INCREMENT BY 1 -- 每次增加1
START WITH 1000 -- 从1000开始
NOMAXVALUE -- 无最大值(或 MAXVALUE 9999)
NOCYCLE -- 不循环
CACHE 20; -- 缓存20个序列值以提高性能
2. 使用序列
INSERT INTO employees (employee_id, first_name, last_name, email)
VALUES (seq_emp_id.NEXTVAL, '张', '三', 'zhangsan@example.com');
SELECT seq_emp_id.CURRVAL FROM dual;
3. 管理序列
-- 修改序列(不能修改START WITH,通常用于修改增量、缓存值等)
ALTER SEQUENCE seq_emp_id INCREMENT BY 2;
-- 删除序列
DROP SEQUENCE seq_emp_id;
四、索引(Index):加速查询的引擎
索引是一种提高数据检索速度的数据库结构,类似于书的目录。
1. 创建索引
CREATE INDEX idx_emp_last_name ON employees(last_name); CREATE INDEX idx_emp_dept_salary ON employees(department_id, salary DESC); - 唯一索引:(通常由UNIQUE或PRIMARY KEY约束自动创建,也可手动)
CREATE UNIQUE INDEX idx_emp_email ON employees(email);
2. 管理索引
-- 重建索引(优化索引性能)
ALTER INDEX idx_emp_last_name REBUILD;
-- 删除索引
DROP INDEX idx_emp_last_name; 索引使用场景:
注意事项:
五,作业
1.Views表:
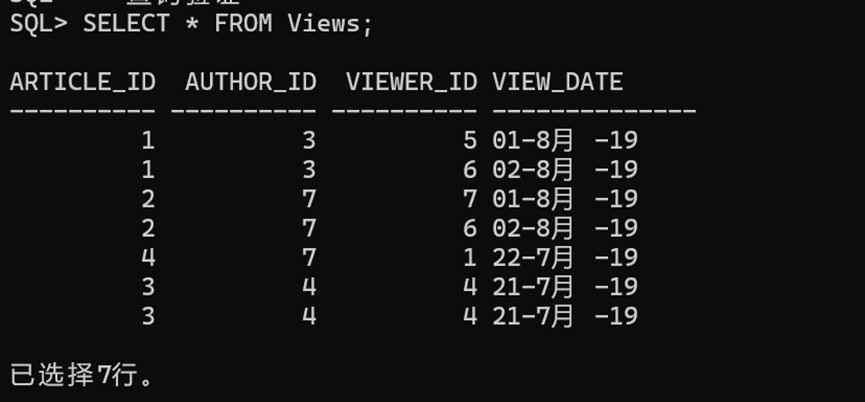
| Column Name | Type | | article_id | int | | author_id | int | | viewer_id | int | | view_date | data |
此表可能会存在重复行。(换句话说,在 SQL 中这个表没有主键)
此表的每一行都表示某人在某天浏览了某位作者的某篇文章。
请注意,同一人的 author_id 和 viewer_id 是相同的。
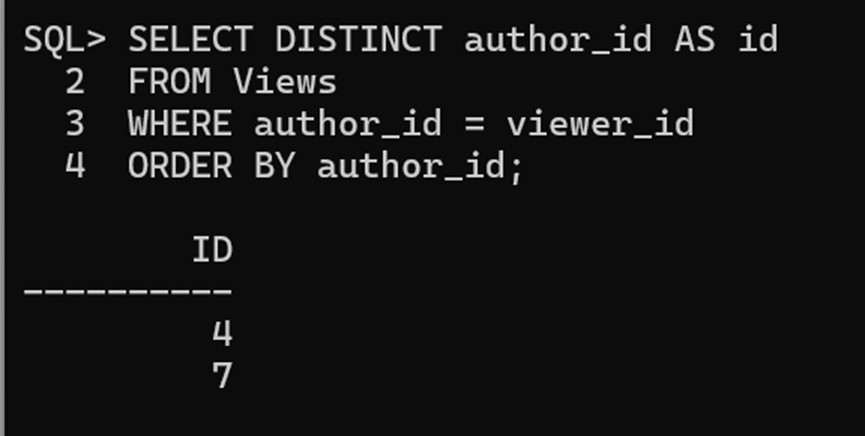
请查询出所有浏览过自己文章的作者。
结果按照作者的 id 升序排列。
查询结果的格式如下所示:
输入:
-- 创建 Views 表
CREATE TABLE Views (
article_id INT,
author_id INT,
viewer_id INT,
view_date DATE
);
-- 插入示例数据
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (1, 3, 5, DATE '2019-08-01');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (1, 3, 6, DATE '2019-08-02');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (2, 7, 7, DATE '2019-08-01');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (2, 7, 6, DATE '2019-08-02');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (4, 7, 1, DATE '2019-07-22');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (3, 4, 4, DATE '2019-07-21');
INSERT INTO Views (article_id, author_id, viewer_id, view_date) VALUES (3, 4, 4, DATE '2019-07-21');
-- 查询验证
SELECT * FROM Views;输入结果:
输出:
SELECT DISTINCT author_id AS id
FROM Views
WHERE author_id = viewer_id
ORDER BY author_id; 输出结果:
2、表:Tweets
| Column Name | Type | | tweet_id | int | | content | varchar |
在 SQL 中,tweet_id 是这个表的主键。
content 只包含字母数字字符,'!',' ',不包含其它特殊字符。
这个表包含某社交媒体 App 中所有的推文。
查询所有无效推文的编号(ID)。当推文内容中的字符数严格大于 15 时,该推文是无效的。
以任意顺序返回结果表。
查询结果格式如下所示:
输入:
-- 创建 Tweets 表
CREATE TABLE Tweets (
tweet_id INT PRIMARY KEY,
content VARCHAR2(4000)
);
-- 插入示例数据
INSERT INTO Tweets (tweet_id, content) VALUES (1, 'Vote for Biden');
INSERT INTO Tweets (tweet_id, content) VALUES (2, 'Let us make America great again!');
-- 查询验证
SELECT * FROM Tweets;输入结果:
输出:
SELECT tweet_id
FROM Tweets
WHERE LENGTH(content) > 15; 输出结果:
3、表:Visits
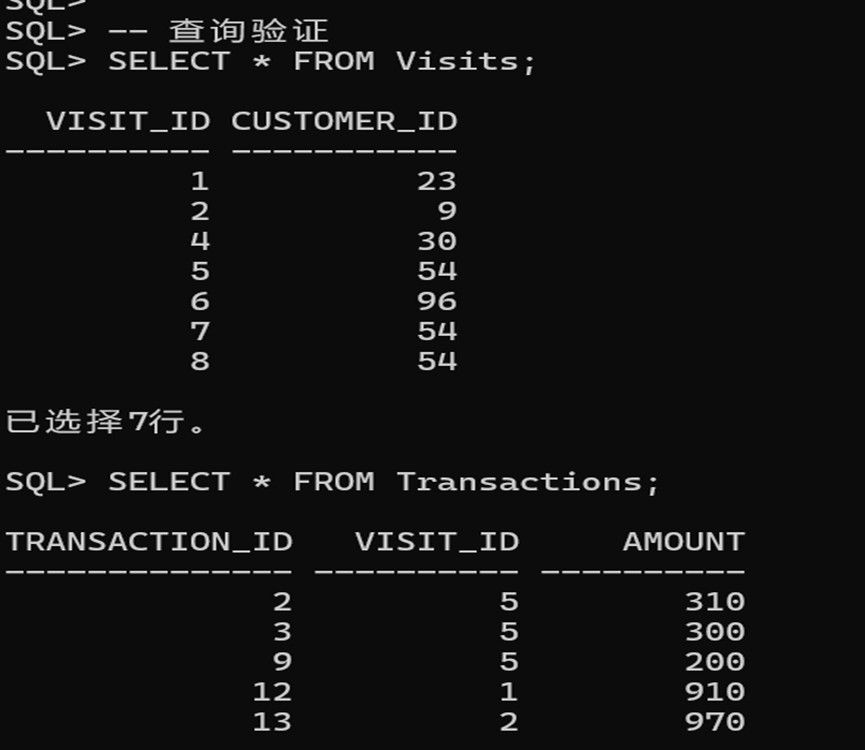
| Column Name | Type | | visit_id | int | | customer_id | int |
visit_id 是该表中具有唯一值的列。
该表包含有关光临过购物中心的顾客的信息
| Column Name | Type | | transaction_id | int | | visit_id | int | | amount | int |
transaction_id 是该表中具有唯一值的列。
此表包含 visit_id 期间进行的交易的信息。
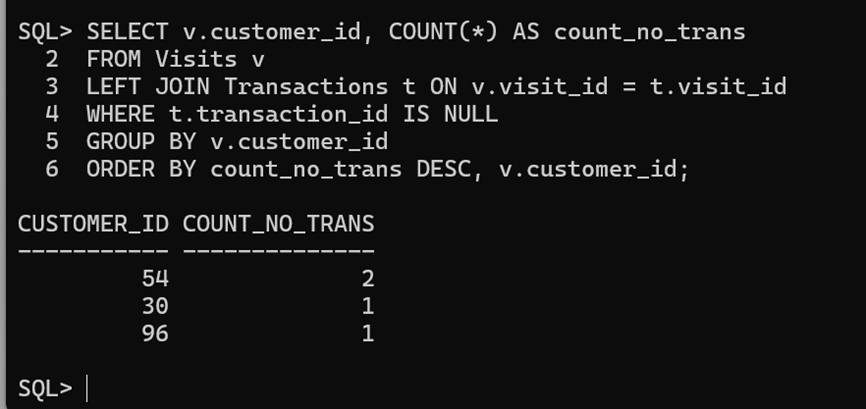
有一些顾客可能光顾了购物中心但没有进行交易。请你编写一个解决方案,来查找这些顾客的 ID ,以及他们只光顾不交易的次数。
返回以 任何顺序 排序的结果表。
返回结果格式如下例所示。
输入:
-- 创建 Visits 表
CREATE TABLE Visits (
visit_id INT PRIMARY KEY,
customer_id INT
);
-- 创建 Transactions 表
CREATE TABLE Transactions (
transaction_id INT PRIMARY KEY,
visit_id INT,
amount INT
);
-- 插入 Visits 示例数据
INSERT INTO Visits (visit_id, customer_id) VALUES (1, 23);
INSERT INTO Visits (visit_id, customer_id) VALUES (2, 9);
INSERT INTO Visits (visit_id, customer_id) VALUES (4, 30);
INSERT INTO Visits (visit_id, customer_id) VALUES (5, 54);
INSERT INTO Visits (visit_id, customer_id) VALUES (6, 96);
INSERT INTO Visits (visit_id, customer_id) VALUES (7, 54);
INSERT INTO Visits (visit_id, customer_id) VALUES (8, 54);
-- 插入 Transactions 示例数据
INSERT INTO Transactions (transaction_id, visit_id, amount) VALUES (2, 5, 310);
INSERT INTO Transactions (transaction_id, visit_id, amount) VALUES (3, 5, 300);
INSERT INTO Transactions (transaction_id, visit_id, amount) VALUES (9, 5, 200);
INSERT INTO Transactions (transaction_id, visit_id, amount) VALUES (12, 1, 910);
INSERT INTO Transactions (transaction_id, visit_id, amount) VALUES (13, 2, 970);
-- 查询验证
SELECT * FROM Visits;
SELECT * FROM Transactions;输入结果:
输出:
SELECT v.customer_id, COUNT(*) AS count_no_trans
FROM Visits v
LEFT JOIN Transactions t ON v.visit_id = t.visit_id
WHERE t.transaction_id IS NULL
GROUP BY v.customer_id
ORDER BY count_no_trans DESC, v.customer_id; 输出结果:
总结 |


 发表于 2025-11-5 11:33:20
发表于 2025-11-5 11:33:20