视频演示
基于深度学习的非机动车头盔检测系统
1. 前言
大家好,欢迎走进 Coding 茶水间。
在城市骑行安全日益受关注的当下,我们想和大家分享一个用技术守护出行的小成果——基于 YOLO 算法的非机动车头盔检测系统。它的核心很简单:帮我们快速判断骑车人有没有戴头盔,用直观的界面和灵活的功能,把“安全检测”变成可操作、可观察的过程。
这套系统不只是“能检测”这么简单:从主界面的分区设计,到参数调节、实时画面展示、检测结果列表与统计,再到登录管理、脚本化检测甚至模型训练脚本,我们把“从用起来到改起来”的全流程都做了落地。无论你是想快速试一张图片、跑一段视频,还是想用自己的数据训一套模型,它都能接住需求。
接下来的内容,我们会从界面布局说起,一步步演示检测、过滤、摄像头调用、登录与个人中心,再到无界面脚本检测、模型训练的完整流程,最后捋一捋目录结构和训练结果的看点。希望这个“能看、能用、能改”的系统,能让大家对 YOLO 在实际场景里的应用,多一份直观的感受。
2. 项目演示
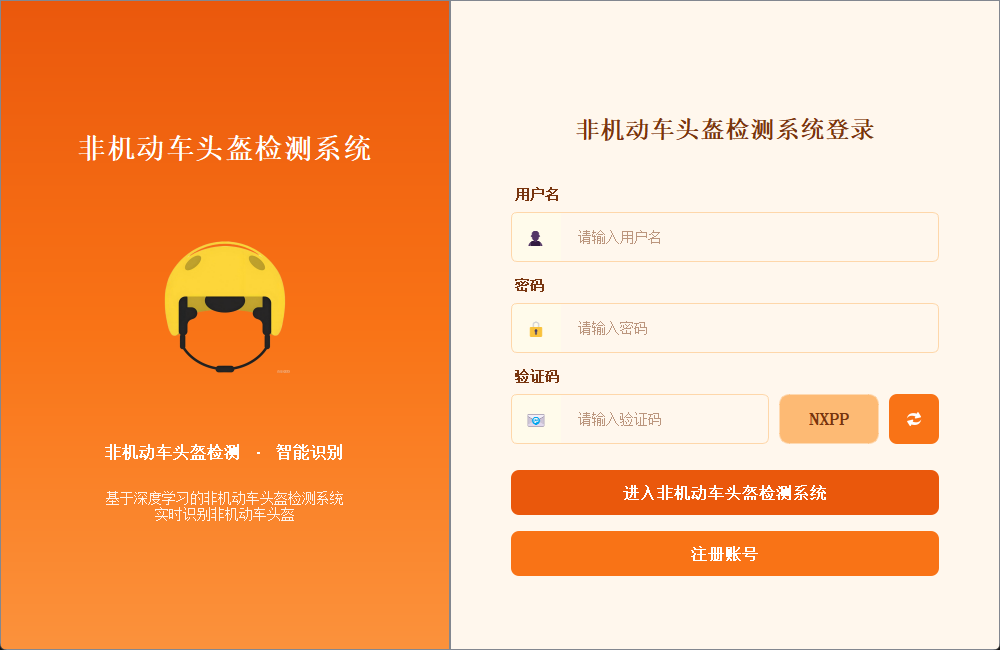
2.1 用户登录界面
登录界面布局简洁清晰,左侧展示系统主题,用户需输入用户名、密码及验证码完成身份验证后登录系统。
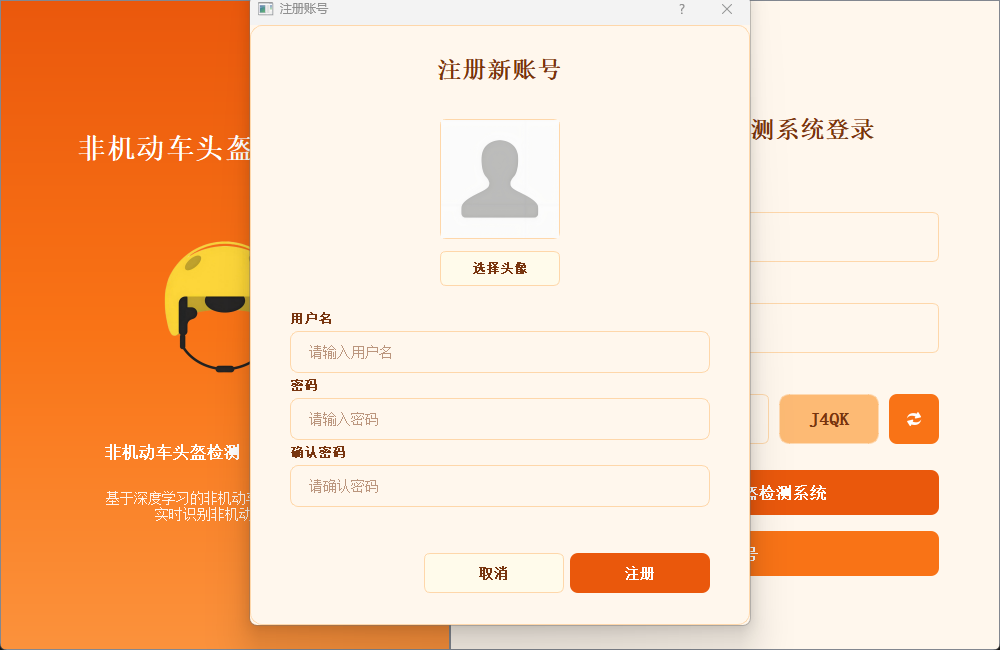
2.2 新用户注册
注册时可自定义用户名与密码,支持上传个人头像;如未上传,系统将自动使用默认头像完成账号创建。
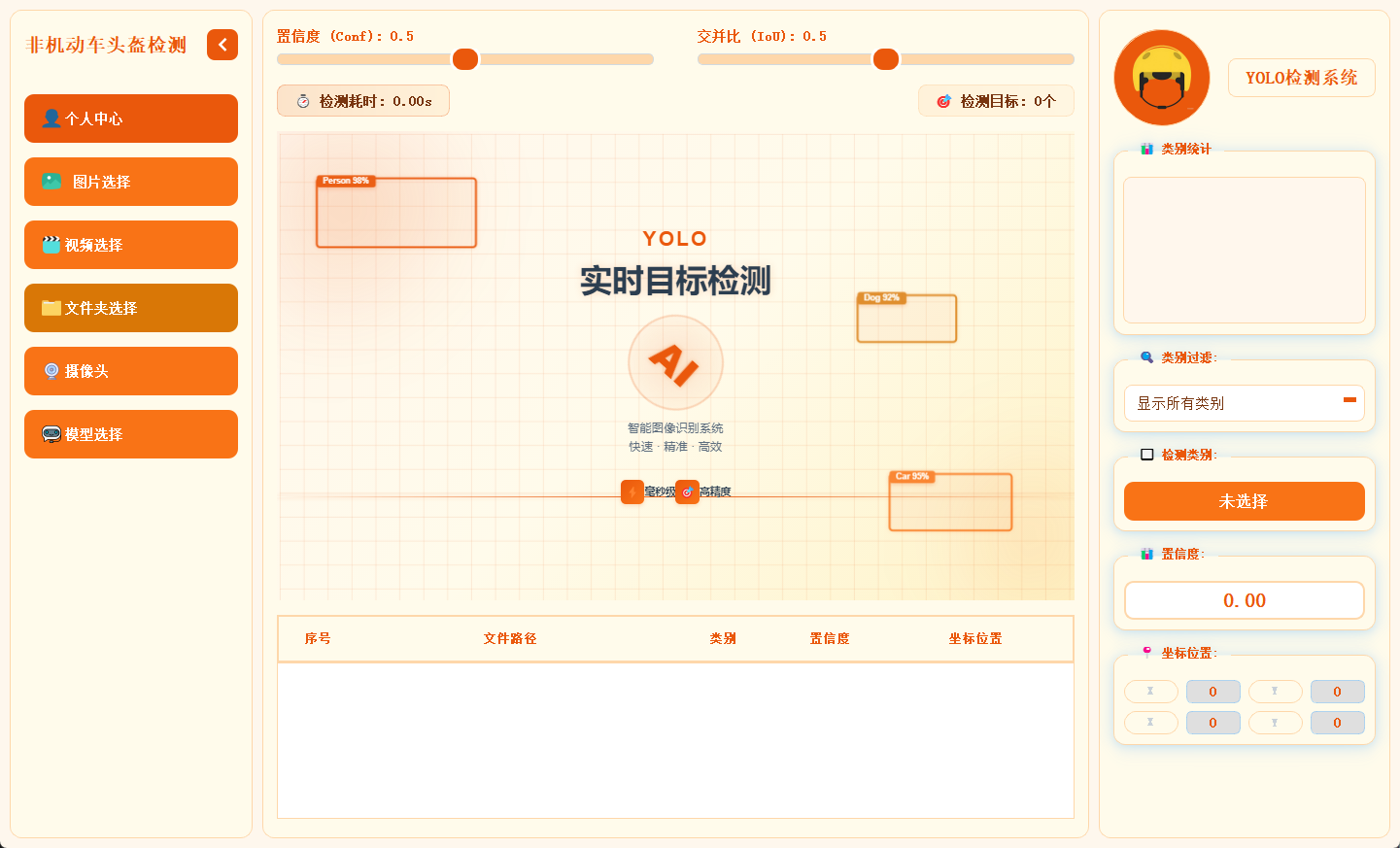
2.3 主界面布局
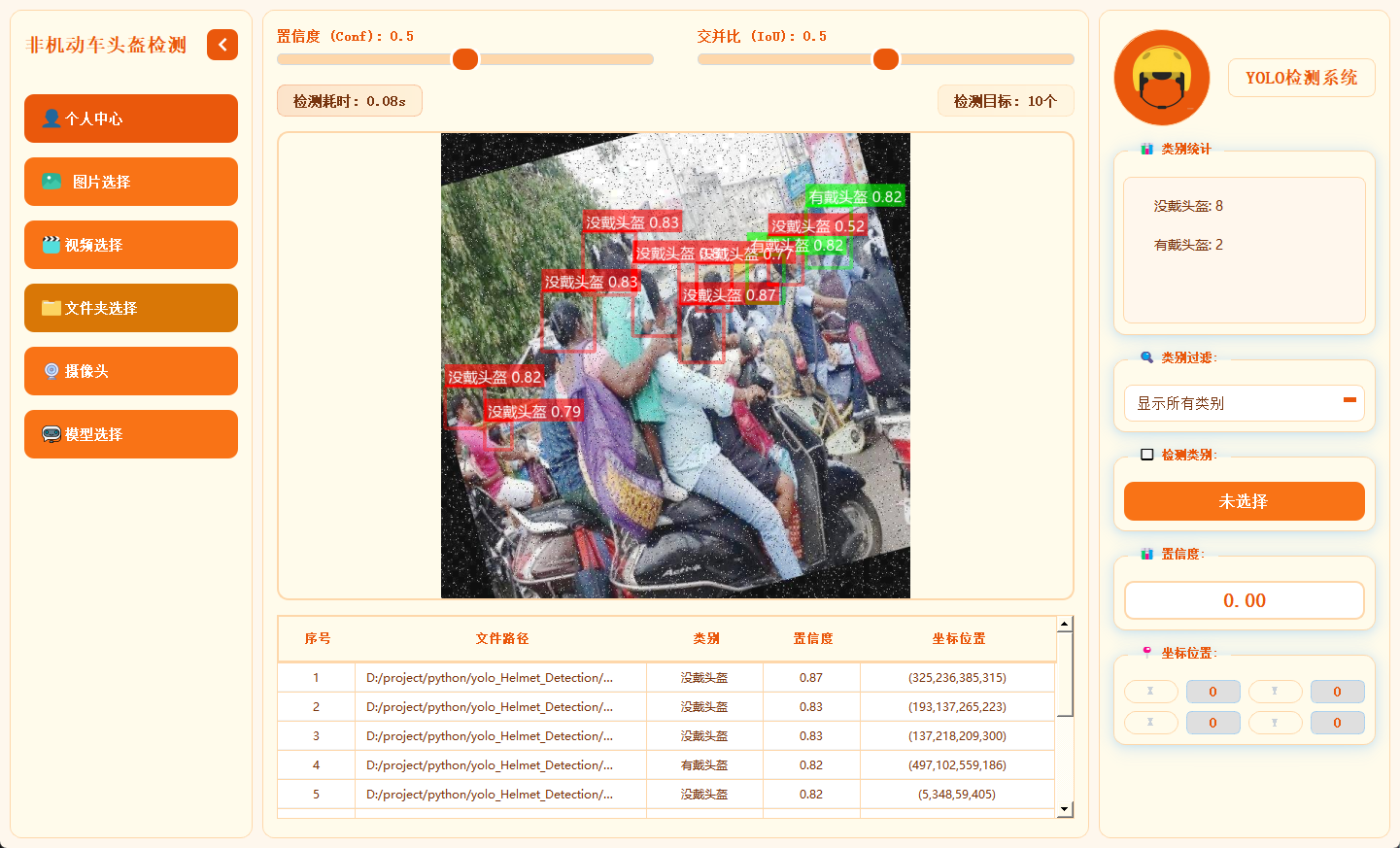
主界面采用三栏结构,左侧为功能操作区,中间用于展示检测画面,右侧呈现目标详细信息,布局合理,交互流畅。
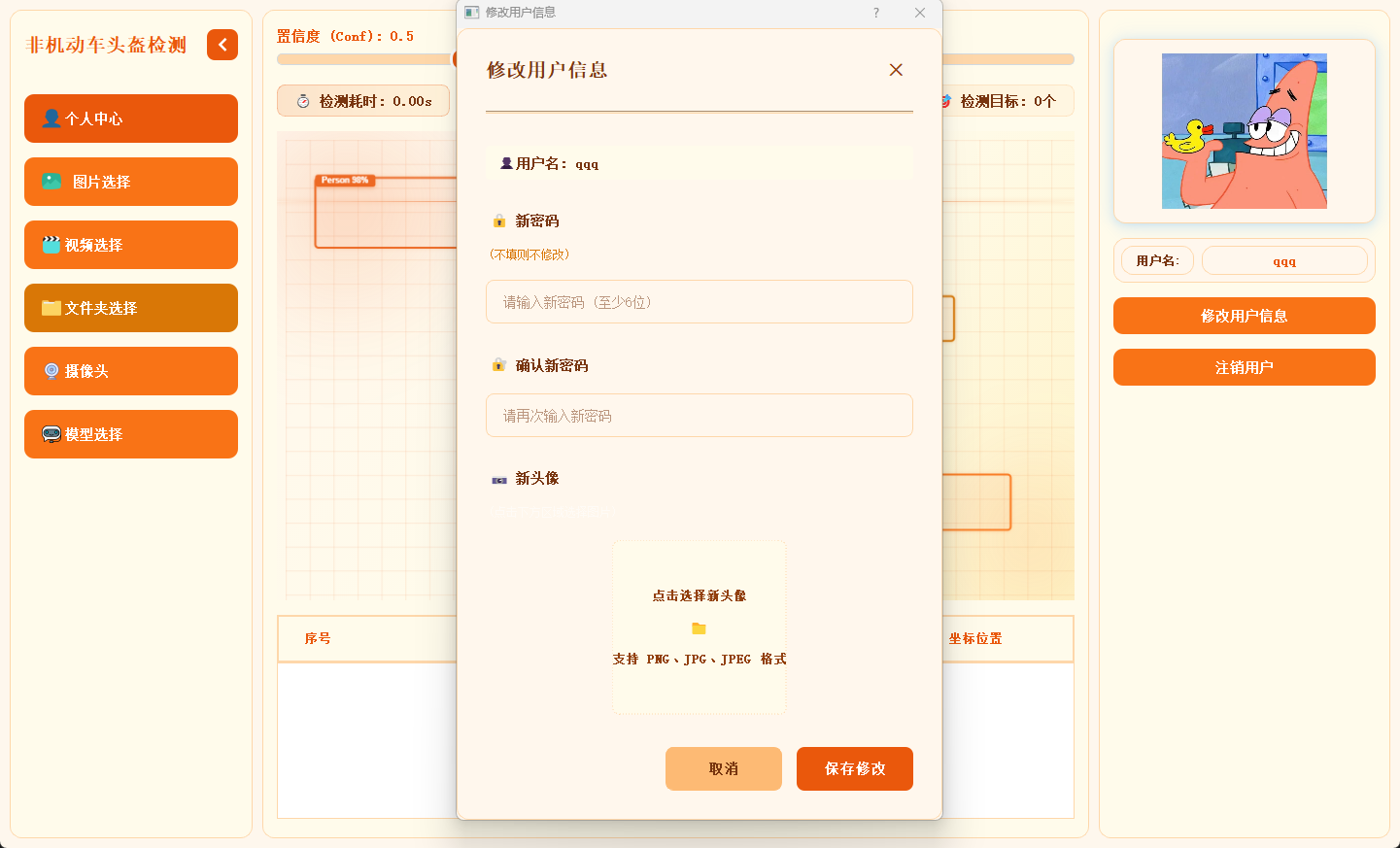
2.4 个人信息管理
用户可在此模块中修改密码或更换头像,个人信息支持随时更新与保存。
2.5 多模态检测展示
系统支持图片、视频及摄像头实时画面的目标检测。识别结果将在画面中标注显示,并在下方列表中逐项列出。点击具体目标可查看其类别、置信度及位置坐标等详细信息。
2.6 多模型切换
系统内置多种已训练模型,用户可根据实际需求灵活切换,以适应不同检测场景或对比识别效果。
3.模型训练核心代码
本脚本是YOLO模型批量训练工具,可自动修正数据集路径为绝对路径,从pretrained文件夹加载预训练模型,按设定参数(100轮/640尺寸/批次8)一键批量训练YOLOv5nu/v8n/v11n/v12n模型。
4. 技术栈
5. YOLO模型对比与识别效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比
基于Ultralytics官方COCO数据集训练结果:
|
模型
|
尺寸(像素)
|
mAPval 50-95
|
速度(CPU ONNX/毫秒)
|
参数(M)
|
FLOPs(B)
|
|
YOLO12n
|
640
|
40.6
|
-
|
2.6
|
6.5
|
|
YOLO11n
|
640
|
39.5
|
56.1 ± 0.8
|
2.6
|
6.5
|
|
YOLOv8n
|
640
|
37.3
|
80.4
|
3.2
|
8.7
|
|
YOLOv5nu
|
640
|
34.3
|
73.6
|
2.6
|
7.7
|
关键结论:
-
精度最高:YOLO12n(mAP 40.6%),显著领先其他模型(较YOLOv5nu高约6.3个百分点);
-
速度最优:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,适合实时轻量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu参数量均为2.6M,FLOPs较低(YOLO12n/11n仅6.5B);YOLOv8n参数量(3.2M)与计算量(8.7B)最高,但精度优势不明显。
综合推荐:
-
追求高精度:优先选YOLO12n(精度与效率兼顾);
-
需高速低耗:选YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣势,无特殊需求时不建议首选。
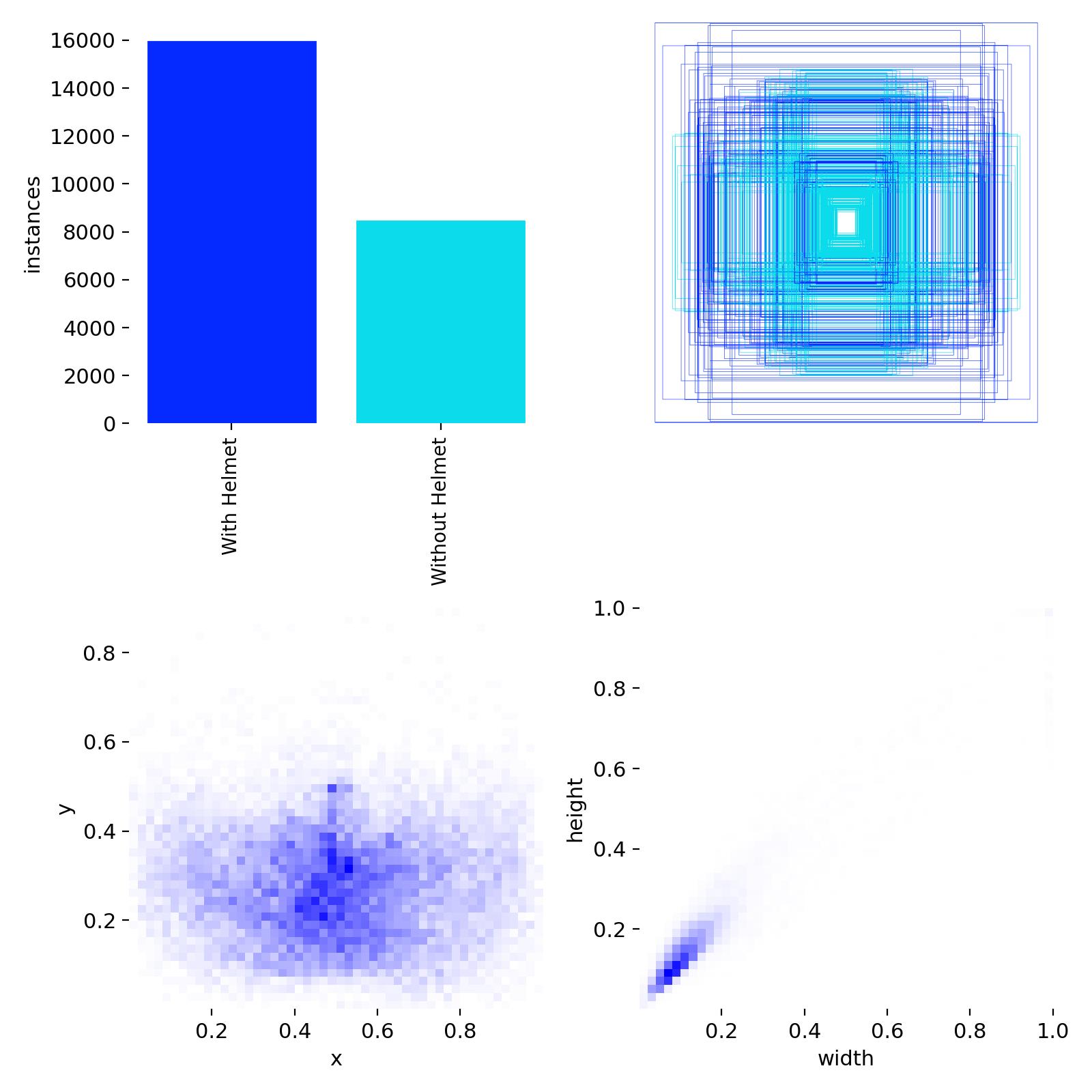
5.2 数据集分析
数据集中训练集和验证集一共13000张图片,数据集目标类别两种:正常肾脏,肾结石ingFang SC", "Smart Quotes", -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif">,数据集配置代码如下:
上面的图片就是部分样本集训练中经过数据增强后的效果标注。
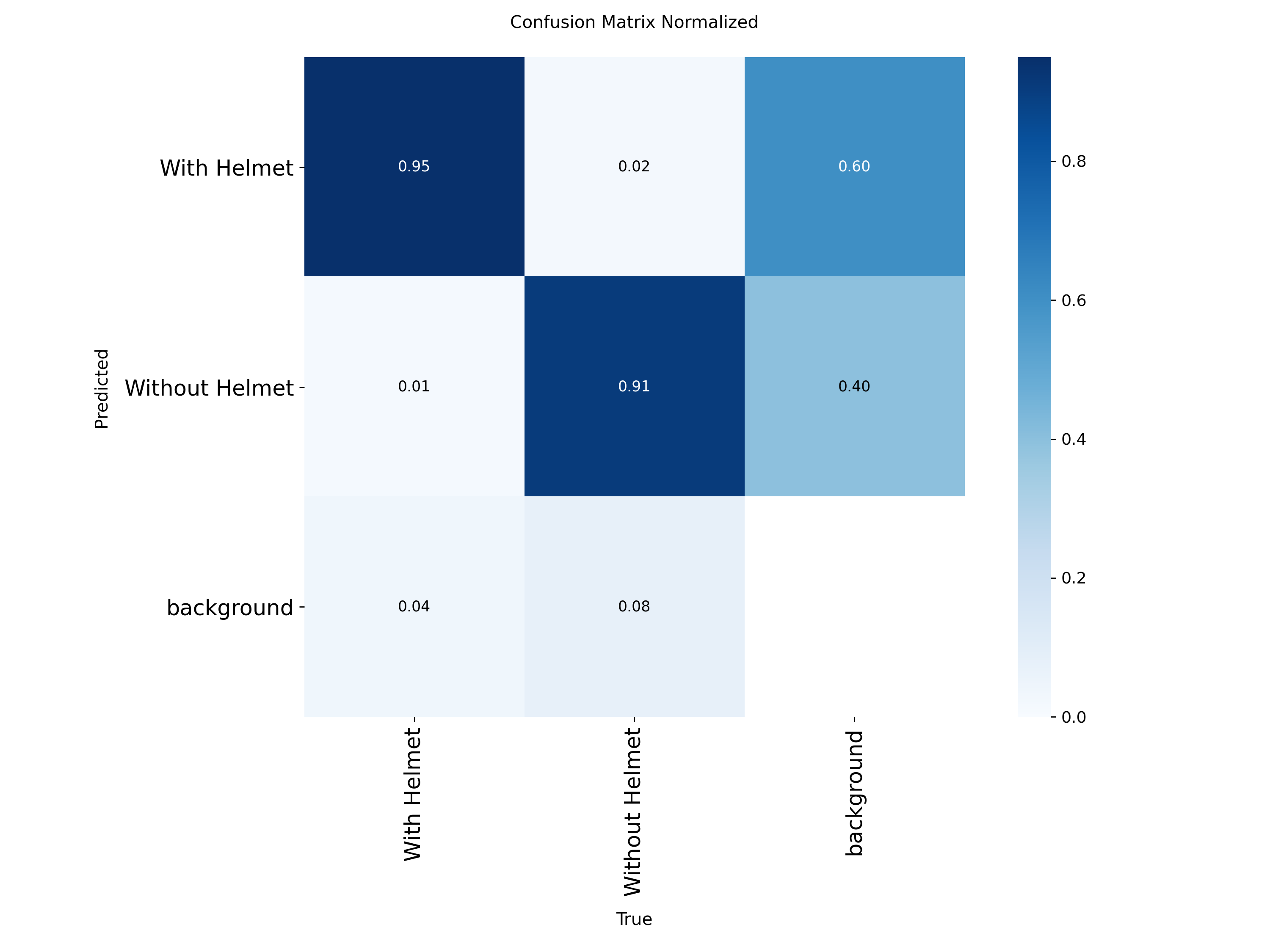
5.3 训练结果
混淆矩阵显示中识别精准度显示是一条对角线,方块颜色越深代表对应的类别识别的精准度越高ingFang SC", "Smart Quotes", -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif">。
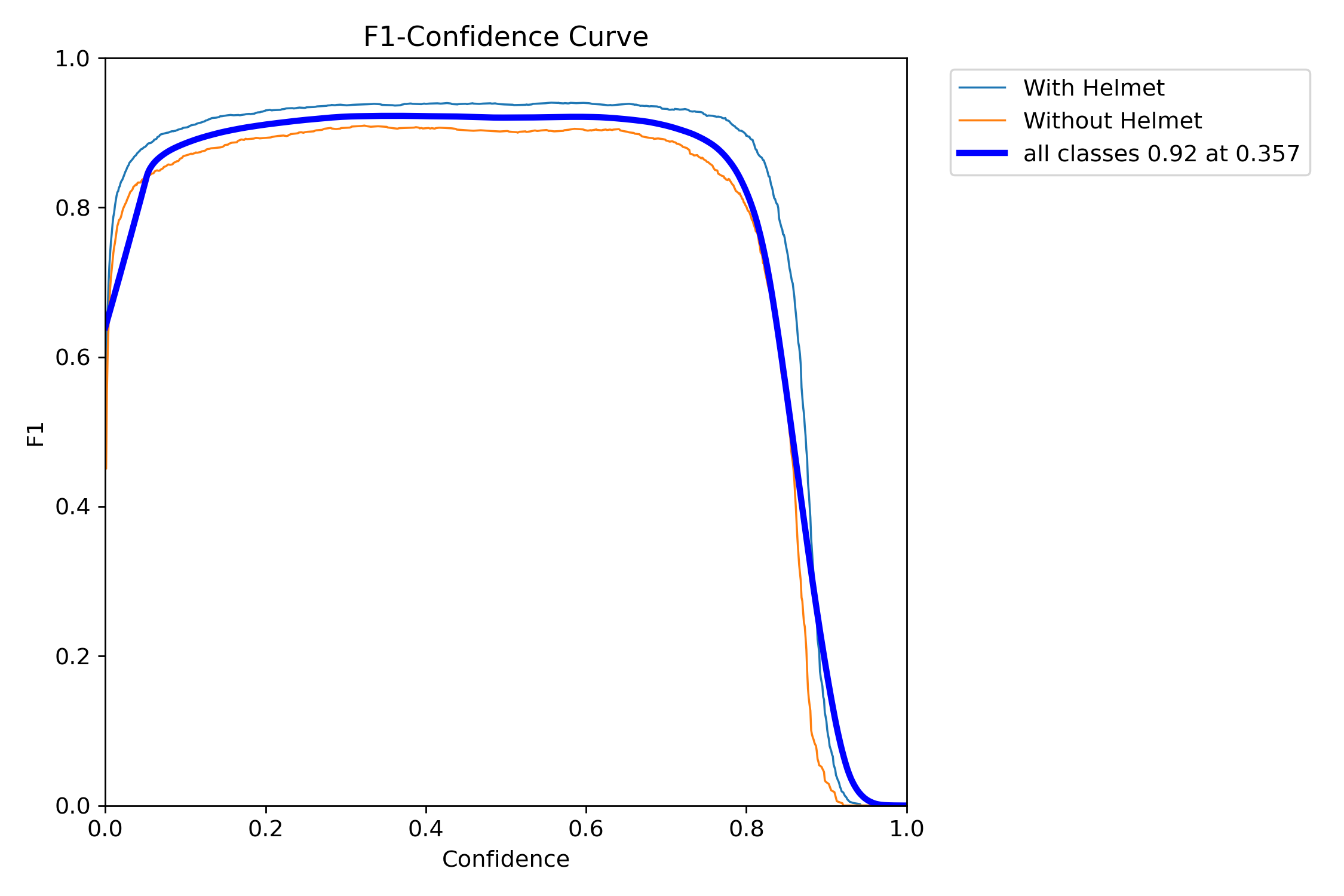
F1指数(F1 Score)是统计学和机器学习中用于评估分类模型性能的核心指标,综合了模型的精确率(Precision)和召回率(Recall),通过调和平均数平衡两者的表现。
当置信度为0.357时,所有类别的综合F1值达到了0.92(蓝色曲线)。
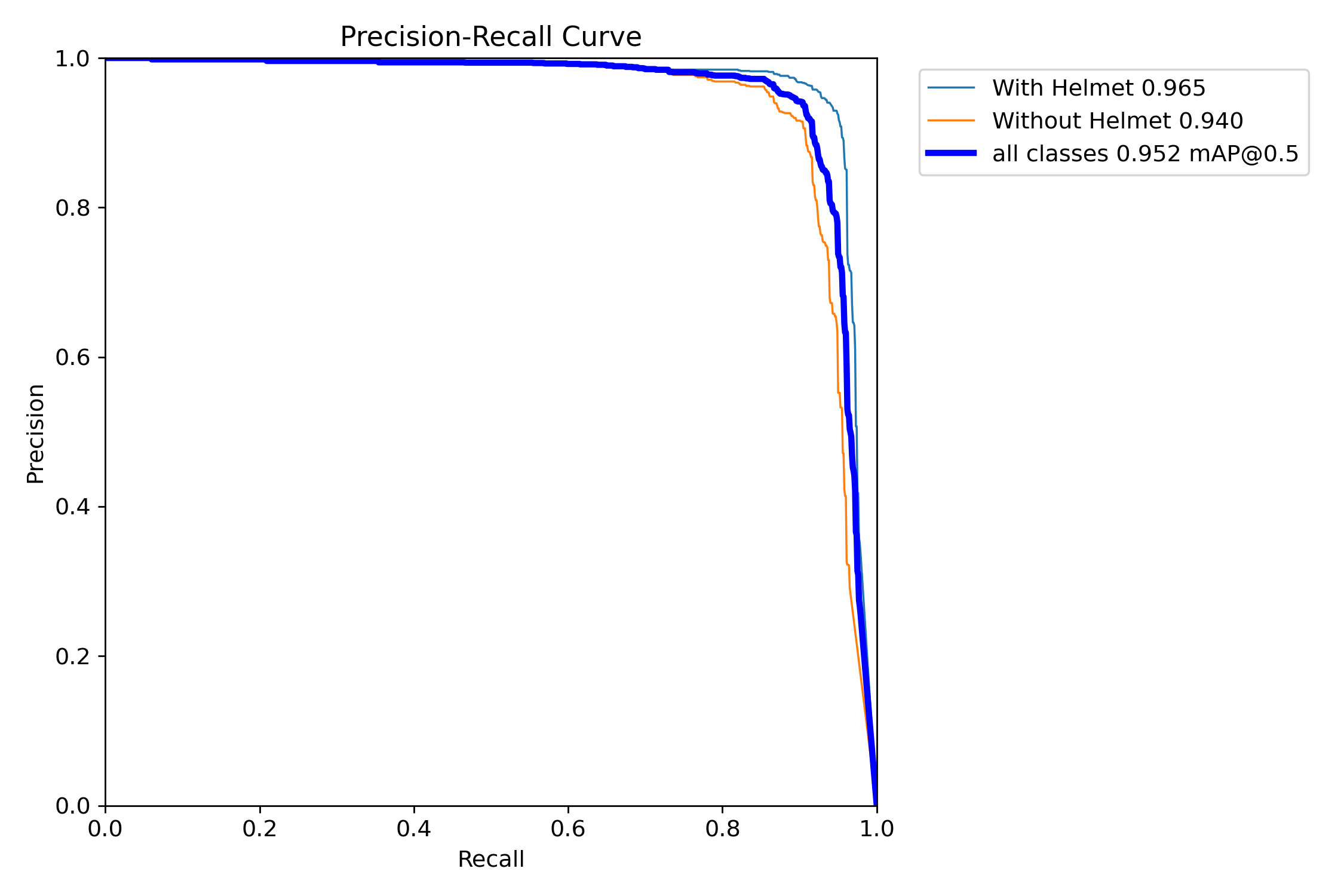
mAP@0.5:是目标检测任务中常用的评估指标,表示在交并比(IoU)阈值为0.5时计算的平均精度均值(mAP)。其核心含义是:只有当预测框与真实框的重叠面积(IoU)≥50%时,才认为检测结果正确。
图中可以看到综合mAP@0.5达到了0.952(95.2%),准确率非常高。
6. 源码获取方式
源码获取:https://www.bilibili.com/video/BV1c4SvBxEuo
来源:https://www.cnblogs.com/codingtea/p/19373546 |


 發表於 2025-12-19 20:44:00
發表於 2025-12-19 20:44:00