视频演示
基于深度学习的水果检测系统
1. 前言
大家好,欢迎来到 Coding 茶水间!
今天要为大家介绍的是一款已落地的成品项目 —— 基于深度学习的水果检测系统。在果蔬分拣、品质检测等相关场景的智能化升级中,水果的快速精准检测是提升作业效率、实现标准化分拣的关键,但传统人工检测模式存在效率低、易受主观因素影响、检测精度不均的弊端,而相关检测算法的开发与系统集成又面临专业门槛高、落地调试周期长的痛点。本项目精准解决这一核心需求,本次展示的系统,不仅集成了 YOLOv5、YOLOv8、YOLO11、YOLO12 多版本模型加载、图片 / 视频 / 文件夹批量检测、摄像头实时流分析等核心功能,还加入了置信度调节、目标类别过滤、检测数据 Excel 导出、识别历史追溯及自定义训练权重加载模块,同时区分用户与管理员双端权限,支持脚本化无界面检测与模型自主训练,旨在提供开箱即用、可适配不同水果检测需求的一站式解决方案。接下来,让我们通过详细的功能演示,一同探索这套系统的技术细节与应用价值。
2. 项目演示
2.1 用户登录界面
登录界面布局简洁清晰,用户需输入用户名、密码验证后登录系统。
2.2 主界面布局
主界面采用三栏结构,左侧为功能操作区,中间用于展示检测画面,右侧呈现目标详细信息,布局合理,交互流畅。
2.3 个人信息管理
用户可在此模块中修改密码或更换头像,个人信息支持随时更新与保存。
2.4 多模态检测展示
系统支持图片、视频及摄像头实时画面的目标检测。识别结果将在画面中标注显示,并且带有语音播报提醒,并在下方列表中逐项列出。点击具体目标可查看其类别、置信度及位置坐标等详细信息。
2.5 检测结果保存
可以将检测后的图片、视频进行保存,生成新的图片和视频,新生成的图片和视频中会带有检测结果的标注信息,并且还可以将所有检测结果的数据信息保存到excel中进行,方便查看检测结果。
2.6 多模型切换
系统内置多种已训练模型,用户可根据实际需求灵活切换,以适应不同检测场景或对比识别效果。
2.7 识别历史浏览
系统内支持用户对识别历史进行浏览,以方便用户查看历史识别记录,可以对识别历史的结果图片进行一个点击放大。
2.8 管理员管理用户信息
系统内支持管理员端的登录操作,登录以后可以对用户信息进行编辑修改和删除,以方实现对用户信息的管理操作。
2.9 管理员管理识别历史
系统内支持管理员对识别历史的单条和多条历史记录的一个浏览和删除操作,以方便管理员对识别历史进行管理。
3.模型训练核心代码
本脚本是YOLO模型批量训练工具,可自动修正数据集路径为绝对路径,从pretrained文件夹加载预训练模型,按设定参数(100轮/640尺寸/批次8)一键批量训练YOLOv5nu/v8n/v11n/v12n模型。
4. 技术栈
5. YOLO模型对比与识别效果解析
5.1 YOLOv5/YOLOv8/YOLOv11/YOLOv12模型对比
基于Ultralytics官方COCO数据集训练结果:
|
模型
|
尺寸(像素)
|
mAPval 50-95
|
速度(CPU ONNX/毫秒)
|
参数(M)
|
FLOPs(B)
|
|
YOLO12n
|
640
|
40.6
|
-
|
2.6
|
6.5
|
|
YOLO11n
|
640
|
39.5
|
56.1 ± 0.8
|
2.6
|
6.5
|
|
YOLOv8n
|
640
|
37.3
|
80.4
|
3.2
|
8.7
|
|
YOLOv5nu
|
640
|
34.3
|
73.6
|
2.6
|
7.7
|
关键结论:
-
精度最高:YOLO12n(mAP 40.6%),显著领先其他模型(较YOLOv5nu高约6.3个百分点);
-
速度最优:YOLO11n(CPU推理56.1ms),比YOLOv8n快42%,适合实时轻量部署;
-
效率均衡:YOLO12n/YOLO11n/YOLOv8n/YOLOv5nu参数量均为2.6M,FLOPs较低(YOLO12n/11n仅6.5B);YOLOv8n参数量(3.2M)与计算量(8.7B)最高,但精度优势不明显。
综合推荐:
-
追求高精度:优先选YOLO12n(精度与效率兼顾);
-
需高速低耗:选YOLO11n(速度最快且精度接近YOLO12n);
-
YOLOv5nu/YOLOv8n因性能劣势,无特殊需求时不建议首选。
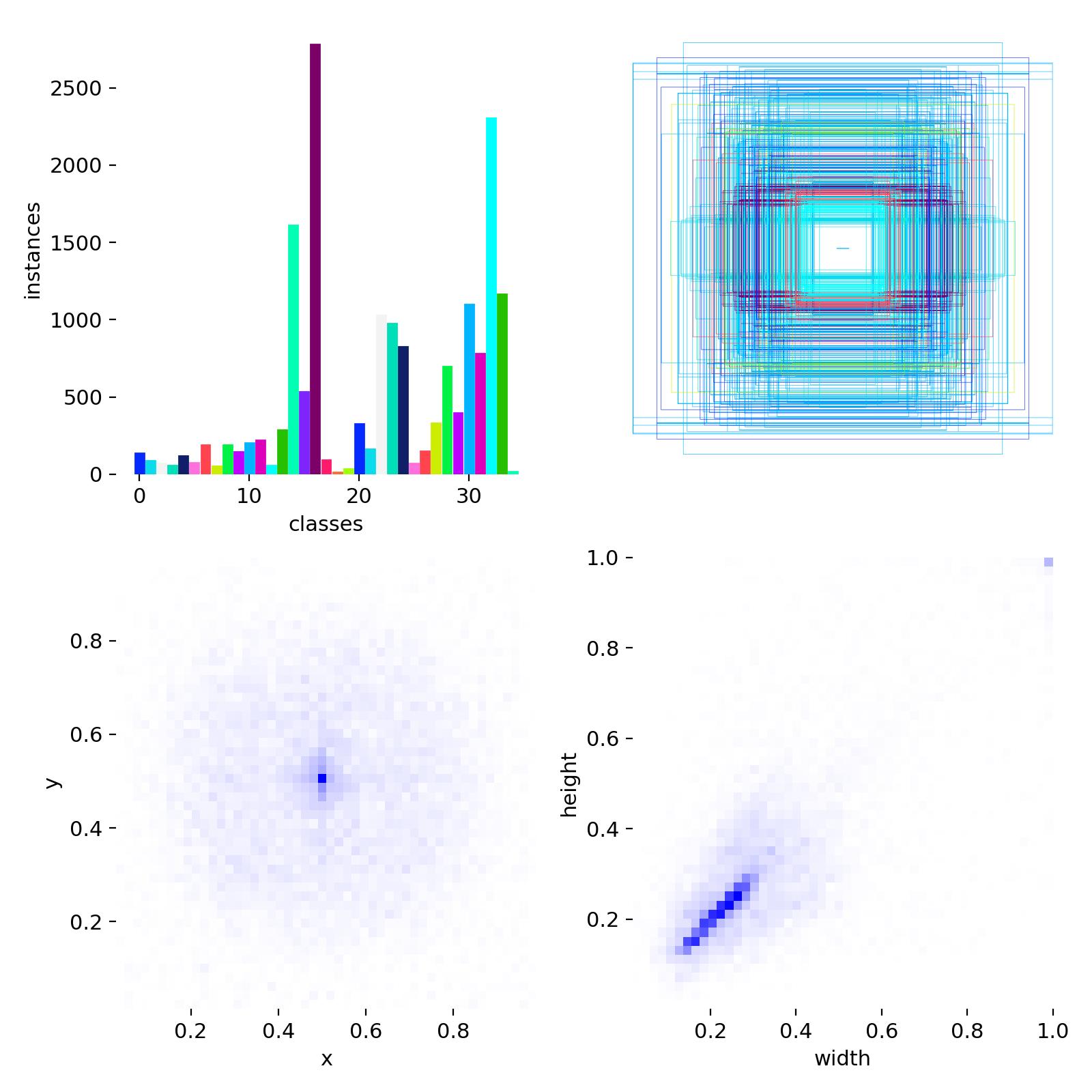
5.2 数据集分析
数据集中训练集和验证集一共7100+张图片,数据集目标类别35种ingFang SC", "Smart Quotes", -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif">,数据集配置代码如下:
上面的图片就是部分样本集训练中经过数据增强后的效果标注。
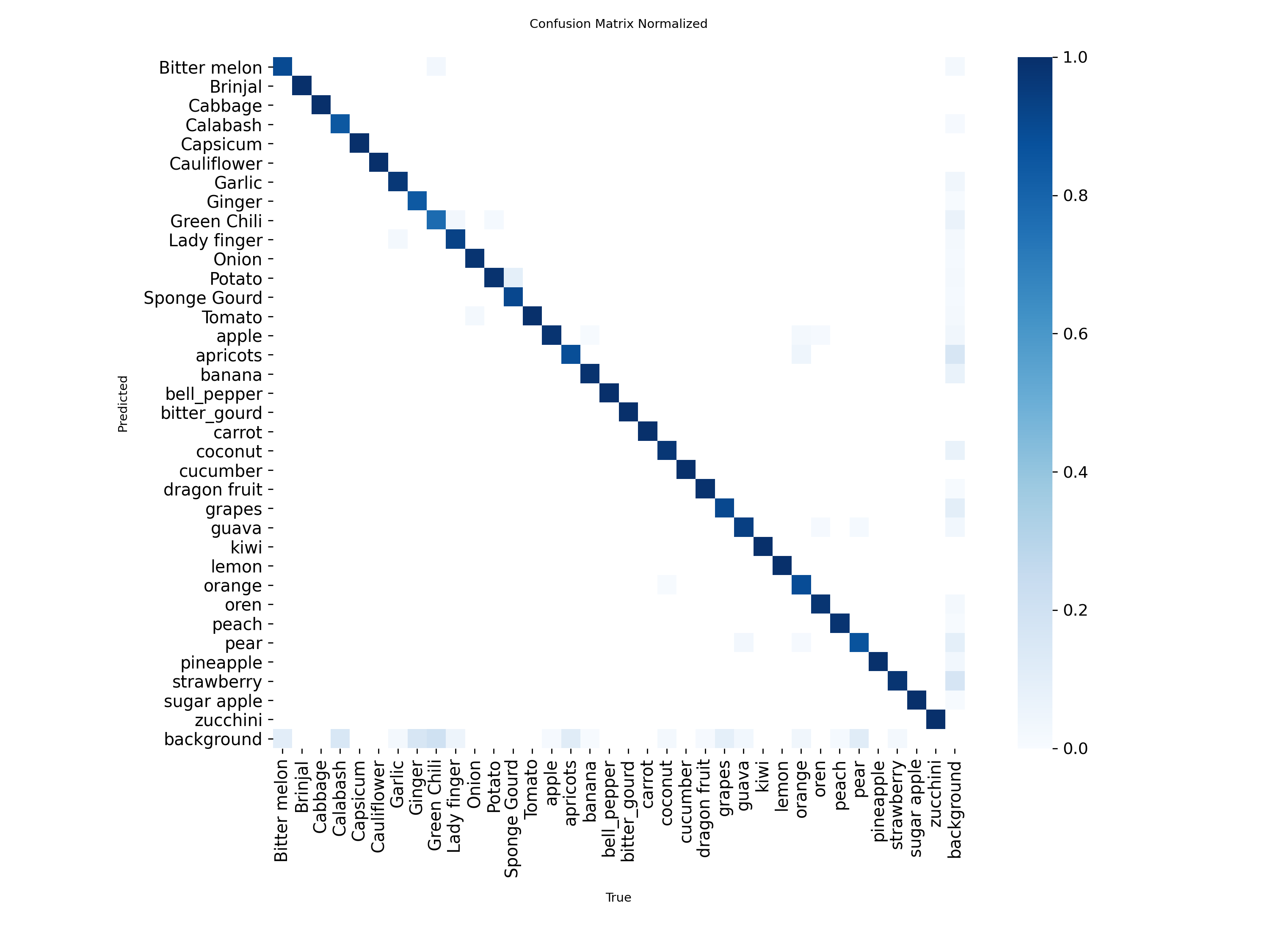
5.3 训练结果
混淆矩阵显示中识别精准度显示是一条对角线,方块颜色越深代表对应的类别识别的精准度越高ingFang SC", "Smart Quotes", -apple-system, BlinkMacSystemFont, "Helvetica Neue", "Microsoft YaHei", "Source Han Sans SC", "Noto Sans CJK SC", "WenQuanYi Micro Hei", sans-serif">。
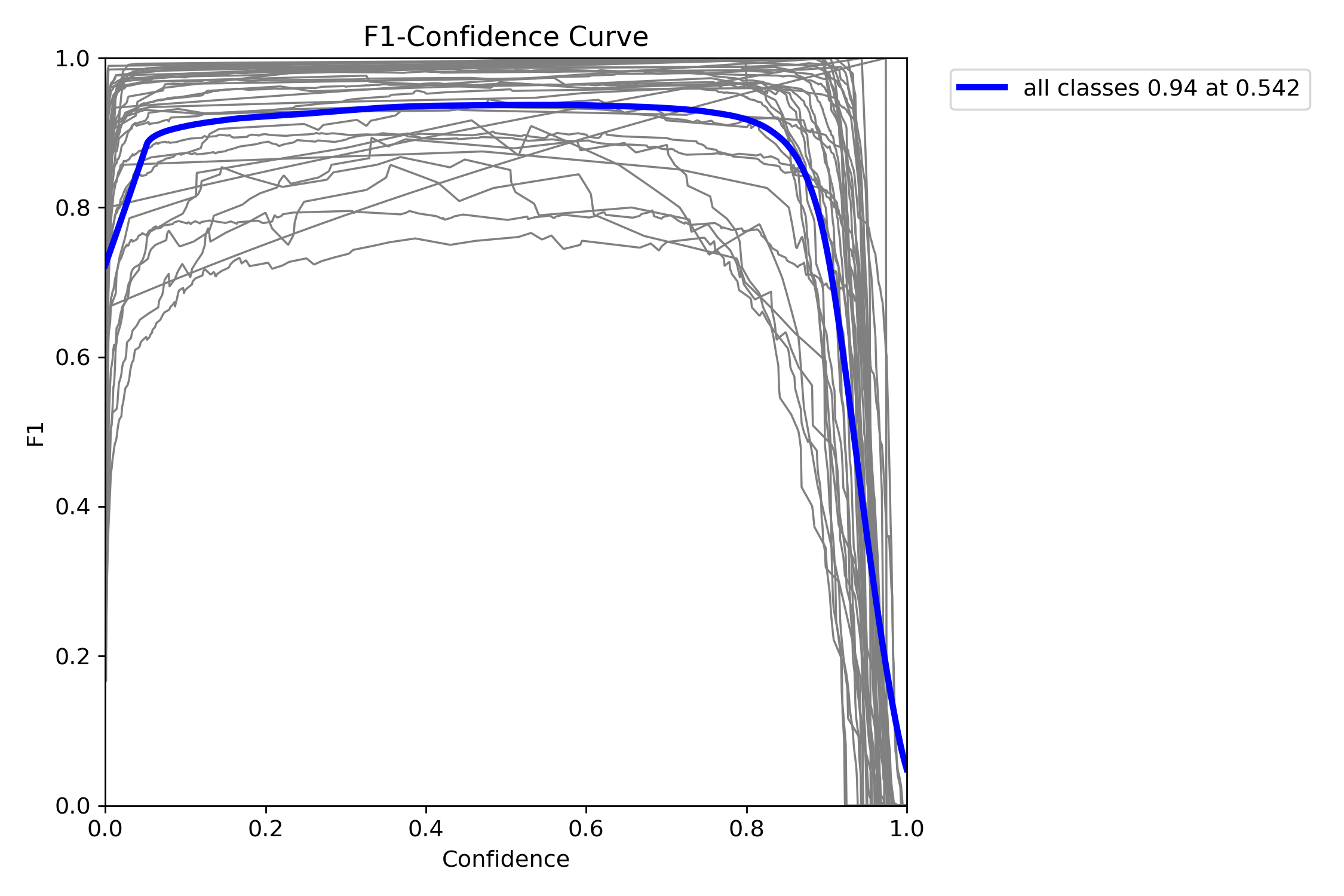
F1指数(F1 Score)是统计学和机器学习中用于评估分类模型性能的核心指标,综合了模型的精确率(Precision)和召回率(Recall),通过调和平均数平衡两者的表现。
当置信度为0.542时,所有类别的综合F1值达到了0.94(蓝色曲线)。
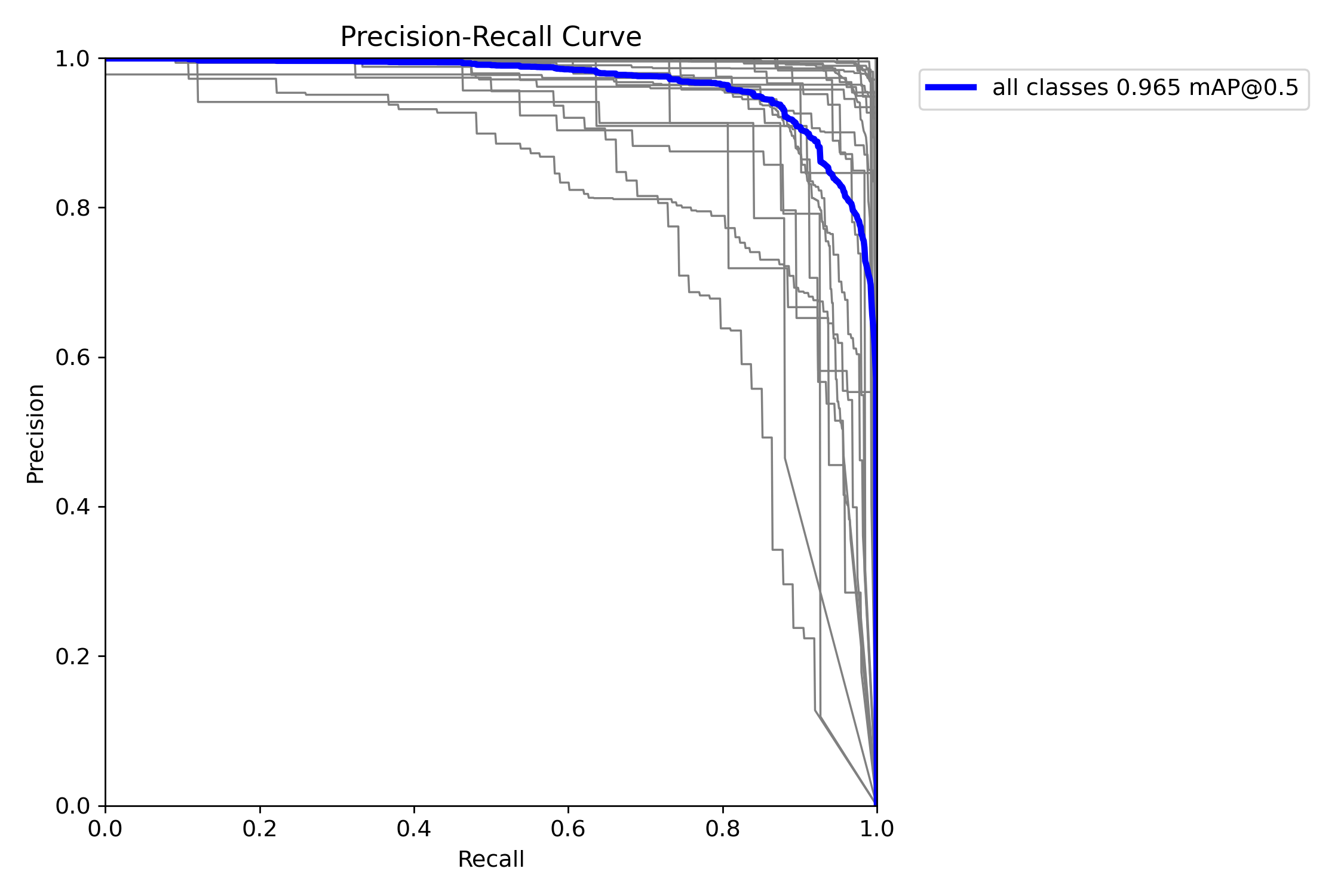
mAP@0.5:是目标检测任务中常用的评估指标,表示在交并比(IoU)阈值为0.5时计算的平均精度均值(mAP)。其核心含义是:只有当预测框与真实框的重叠面积(IoU)≥50%时,才认为检测结果正确。
图中可以看到综合mAP@0.5达到了0.965(96.5%)。
6. 源码获取方式
源码获取方式:https://www.bilibili.com/video/BV1h2z5BREwd/
来源:https://www.cnblogs.com/codingtea/p/19599135 |


 發表於 2026-2-10 13:03:00
發表於 2026-2-10 13:03:00