|
比如执行一条查询语句:
select * from T where ID=10;
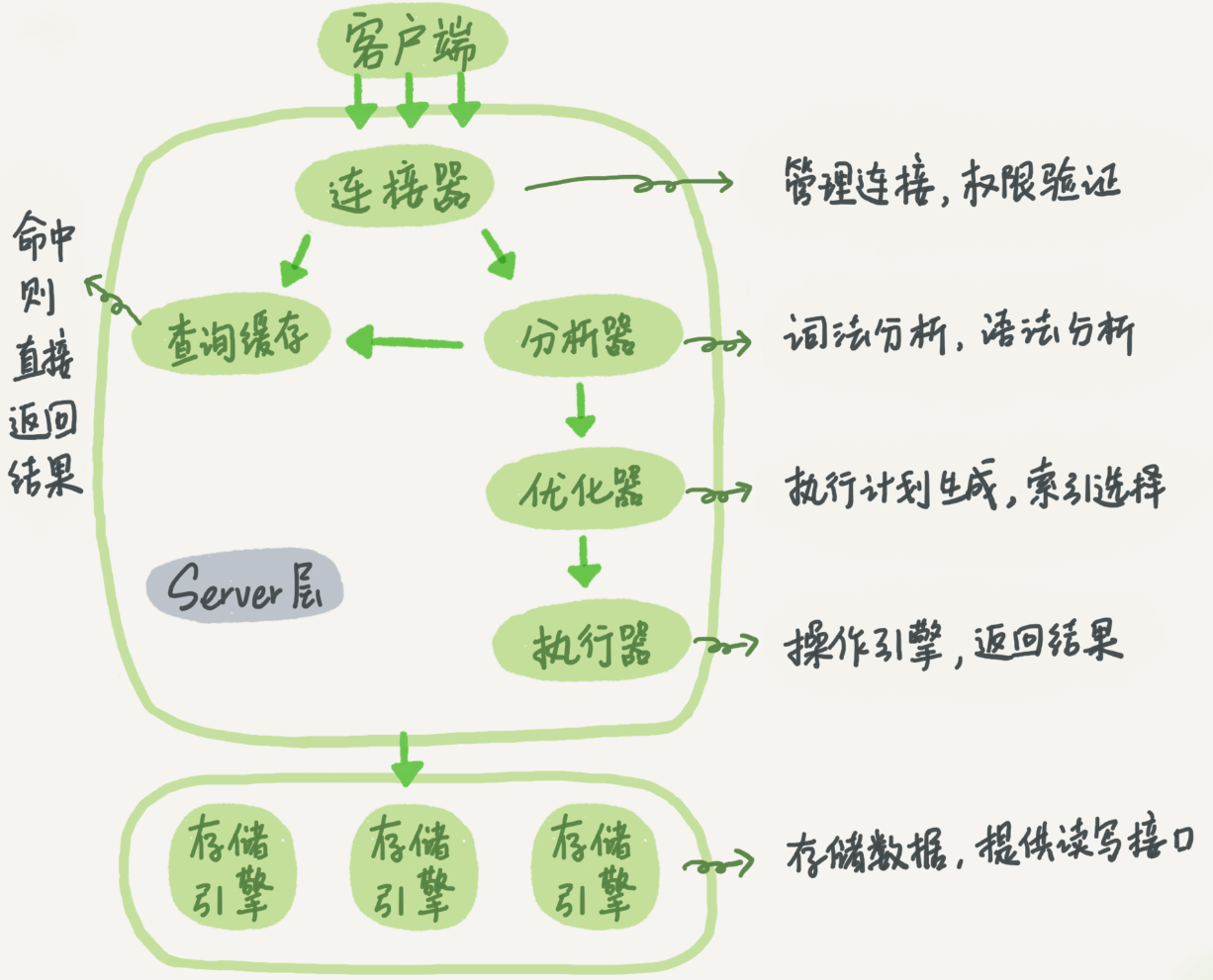
首先给出MySQL的基本架构示意图,从中也可以看到执行过程:
基本结构分为两部分:
再以前面的查询语句为例,来看具体的执行流程:
1. 连接器
连接器负责跟客户端建立连接、获取权限、维持和管理连接。
当用户在客户端输入连接命令和密码,连接器会开始认证身份。
连接完成后,如果没有后续动作,连接会处于空闲状态,到一定时间会自动断开连接。这个时间默认为8小时。如果连接断开,客户端再次发送请求,就会收到错误提醒。
数据库的连接分为两种:
由于建立连接过程比较复杂,建议尽量使用长连接。
但长连接很多的情况下,由于MySQL执行过程使用的内存管理在连接对象里,会导致MySQL内存占用大幅增长,甚至因为太大被系统强制杀掉,造成MySQL异常重启。
对于该问题,考虑两个解决方案:
2. 查询缓存
执行过的查询可能以key-value形式缓存起来,其中key是查询语句,value是查询结果。
如果查询能在缓存中找到,那么就可以直接返回结果给客户端。如果不在缓存中,则继续后面的执行阶段,且执行完成后会将结果存入缓存。
但查询缓存往往弊大于利。因为查询缓存失效很频繁,只要在一张表里做一次更新,这张表的所有查询缓存都会被清空,所以更新多的数据库中查询缓存命中率非常低。从MySQL 8.0开始,已经没有查询缓存了。
3. 分析器
分析器先做词法分析,MySQL会从SQL语句识别出select关键字、把T识别成表名、把ID识别成列名。
然后做语法分析,会判断该语句是否满足语法。比如表名或列名是否有问题。
4. 优化器
优化器是在表中有多个索引时,决定使用哪个索引;或在语句有多表JOIN时,决定各表连接顺序。
5. 执行器
执行器会先判断用户对表有没有执行查询的权限,如果没有则返回错误,如果有则打开表继续执行。
打开表时,执行器会根据表的引擎,去使用这个引擎提供的接口。
比如前面的查询语句,执行器的流程为:
这里“下一行”取引号,代表着如果有索引就不是简单的下一行了。
来源:https://www.cnblogs.com/san-mu/p/18964477 |


 發表於 2025-7-3 21:28:00
發表於 2025-7-3 21:28:00