覆盖索引
假设要执行一条语句:
select * from T where k between 3 and 5;
初始对列k建立了索引,表中数据为:
那么其执行流程为:
这个过程中,发生了回表。假如建立的索引能“覆盖”我们的查询需求,就不需要回表,这种索引称为覆盖索引。比如在上面的查询语句中,若查询的是列k而不是*,就是一个覆盖索引。
需要注意的是,在引擎内部使用覆盖索引在索引k上其实能读到R3-R5三个记录,但是由于Server层只会从引擎得到两条记录,因此MySQL认为扫描行数为2。
最左前缀原则
B+树这种索引结构,可以利用索引的最左前缀,来定位记录。
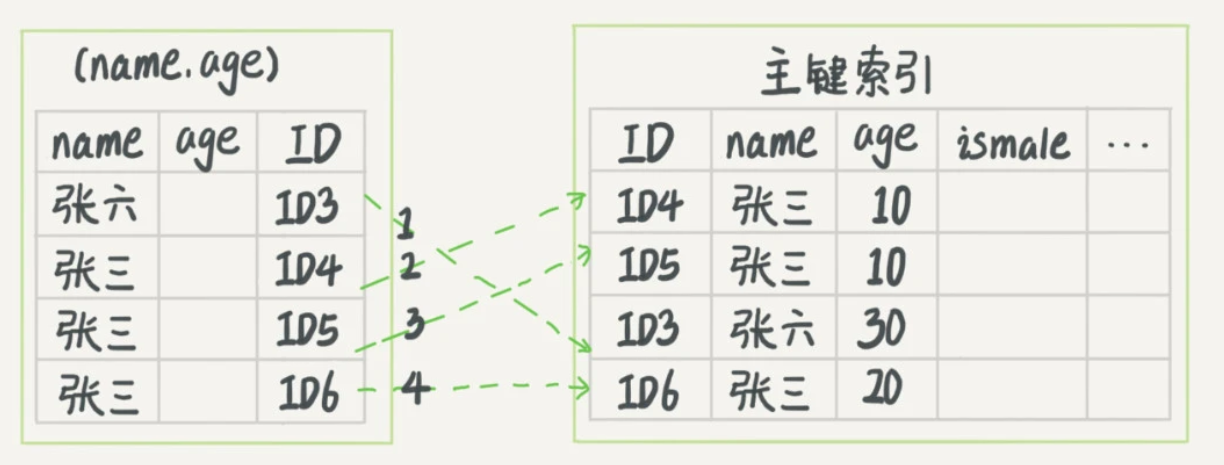
比如建立了(name,age)的联合索引:
当要查询name="张三",可以快速定位到ID4,然后向后遍历。
当要查询where name like "张%",也能用上这个索引,定位到ID3,然后向后遍历。
因此,索引的最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
索引下推
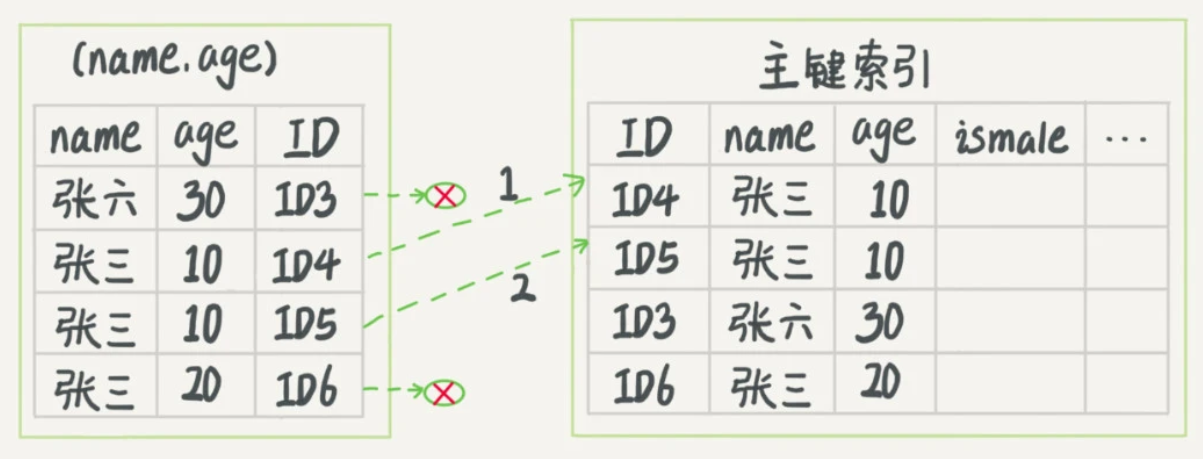
还是假设建立了(name,age)的联合索引,现在有一条SQL语句如下:
select * from tuser where name like '张%' and age=10 and ismale=1;
由最左前缀原则,这条语句能用上name的索引。
而其他条件的判断:
两者的比较如下,第一张图是无索引下推,第二张图是有索引下推,箭头表示回表:
来源:https://www.cnblogs.com/san-mu/p/18967216 |


 發表於 2025-7-6 13:29:00
發表於 2025-7-6 13:29:00