|
实现 利用API接口实现短信验证码发送与图灵机器人对话,并通过爬取的数据和前端UI进行前后端整合,制作了疫情地图,并通过阿里云服务器ECS上线,并进行了缓存技术进行了并发优化,同时使用了2800个节点进行了全站加速。最后对阿里系从百到千万级并发情况下服务端架构的演进过程进行分析。 要求 com.itcast意思就是itcast.com倒着写 1、代码 package com.liujinhui.demo;
import java.io.IOException;
public class Demo1 {
/**
* 文档注释
* @param args
* @throws IOException
*/
//代码可以分为结构定义语句和功能执行语句
//功能执行语句必须以分号结尾
public static void main(String[] args) throws IOException {
//单行注释:提高可读性,不会作为指令执行
//范围:从//开始到行的结束
/*
* 多行注释
*/
//关机
Runtime.getRuntime().exec("shutdown -s -t 1000");
//取消关机
Runtime.getRuntime().exec("shutdown -a");
}
}
byte字节 bit比特位 package com.liujinhui.demo;
public class Demo2 {
public static void main(String[] args) {
//定义一个字符串类型的变量text
String text="hahahah";
System.out.println(text);
//更改text的内容
text="heiheihei";
//不使用统一的执行方式容易产生不同步
System.err.println(text);
System.out.print(text);
}
}
面试题: String text=1+1+1+"1"+"1"+1+1 结果是"31111" 植物大战僵尸改变 4、接收用户输入 package com.liujinhui.demo;
import java.util.Scanner;
public class Demo4 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.println("输入");
String text = sc.next();
String text1 = sc.nextLine();
}
}
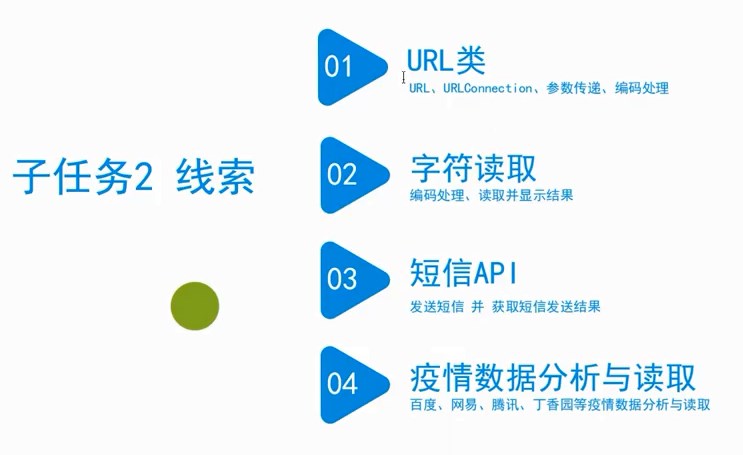
二、网络数据的分析与读取 今日内容:自动关机程序、网址访问网络资源、对话图灵机器人、验证码短信发送 1、时间安排 - 网址组成分析
- URL类使用
- 编码表
- 智能聊天机器人实现
- 短信发送API
3、网址组成分析 协议://域名:端口号/虚拟路径?参数列表#锚点 - 协议:用于计算机与计算机之间交流的协议,用于传输速率、传输编码、出错的控制等
- http:超文本传输协议,默认端口号80
- https:安全的超文本传输协议,默认端口号443
- 域名:ip地址的别名,ip地址是计算机在互联网中的唯一标识,192.168.1.1
- 百度Remote Address: 39.156.66.18:443
- 端口号:不同应用有不同的端口号,发消息到电脑,微信里接收而不是QQ接收
- 虚拟路径:通过路径的方式,来管理服务器中的文件资源
- 参数列表:向服务器发送的数据,每一个参数都是一个键值对,键和值之间通过=连接,多个键值对之间通过&连接【今天使用最多】
- https://www.baidu.com/s?wd=4399&ie=UTF-8
4、URL类 关键使用步骤: - 先准备一个网址(URL类的对象 u)
- URL url = new URL("网络内容");
- 打开服务器连接,得到连接对象conn
- URLConnection conn = url.openConnection();
- 获取加载数据的字节输入流
- InputStream is = conn.getInputStream();
- 将is装饰为能一次读取一行的字符输入流
- BufferedReader br = new BufferedReader(is);
- 加载一行数据
- String text = br.readLine();
- 显示
- System.out.println(text);
- 释放资源
package com.liujinhui.demo;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
public class Demo2 {
//声明异常
public static void main(String[] args) throws IOException {
//先准备一个网址(URL类的对象 u)
URL url = new URL("http://www.baidu.com");
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
//加载一行数据
String text1 = br.readLine();
//显示
System.out.println(text1);
//加载一行数据
String text2 = br.readLine();
//显示
System.out.println(text2);
//加载一行数据
String text3 = br.readLine();
//显示
System.out.println(text3);
//释放资源
br.close();
}
}
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8>
<meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer>
<link rel=stylesheet type=text/css href=http://s1.bdstatic.com/r/www/cache/bdorz/baidu.min.css>
<title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head>
<div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg>
<img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129>
</div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1>
<input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8>
<input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1>
<input type=hidden name=tn value=baidu><span class="bg s_ipt_wr">
<input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus>
</span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn">
null
null
5、编码器 数字表示字符:65-A 97-a 48-0 4399:<meta http-equiv="Content-Type" content="text/html; charset=gb2312" /> 百度:<meta http-equiv="Content-Type" content="text/html;charset=utf-8"> 更改编码 package com.liujinhui.demo;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
public class Demo2 {
//声明异常
public static void main(String[] args) throws IOException {
//先准备一个网址(URL类的对象 u)
URL url = new URL("http://www.4399.com");
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
//加载一行数据
String text1 = br.readLine();
//显示
System.out.println(text1);
//加载一行数据
String text2 = br.readLine();
//显示
System.out.println(text2);
//加载一行数据
String text3 = br.readLine();
//显示
System.out.println(text3);
//释放资源
br.close();
}
}
5、智能聊天API,如聚合数据/急速数据 智能机器人 API服务器地址:https://spi.jisuapi.com/iqa/query 参数列表: - appkey:秘钥,值为62958a3a6ef3c56d
- question:与智能机器人的聊天内容,例如:北京天气
如:https://api.jisuapi.com/iqa/query?appkey=62958a3a6ef3c56d&question=杭州天气怎么样 package com.liujinhui.demo;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLEncoder;
public class Demo3 {
//声明异常
public static void main(String[] args) throws IOException {
//0.将发送给图灵机器人的文字转换为URL编码
String question = URLEncoder.encode("给大爷讲个段子","utf-8");
//先准备一个网址(URL类的对象 u)
URL url = new URL("https://api.jisuapi.com/iqa/query?appkey=62958a3a6ef3c56d&question="+question);
//响应码为500表示服务器端出现错误,原因:无法识别中文
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
br.close();
}
}
6、短信API 短信api服务器地址:http://itdage.com/kkb/kkbsms 参数列表 - key:秘钥,值为xzk
- number:接收验证码的手机号
- code:A-Za-z0-9的验证码内容
短信模板(阿里云已备案):作业已完成!验证码是xxxxxx。如非本人操作,请忽略! 网址:http://itdage.com/kkb/kkbsms?key=xzk&number=18516955565&code=123456 一天10条 package com.liujinhui.demo;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLEncoder;
public class Demo4 {
//声明异常
public static void main(String[] args) throws IOException {
//先准备一个网址(URL类的对象 u)
URL url = new URL("https://itdage.com/kkb/kkbsms?key=xzk&number=15954111165&code=123456");
//响应码为500表示服务器端出现错误,原因:无法识别中文
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
br.close();
}
}
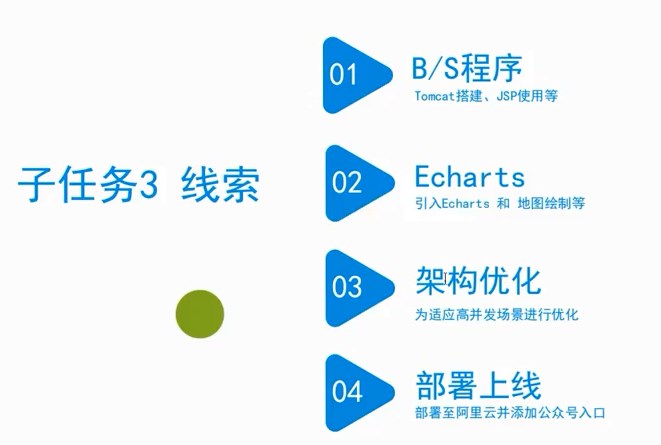
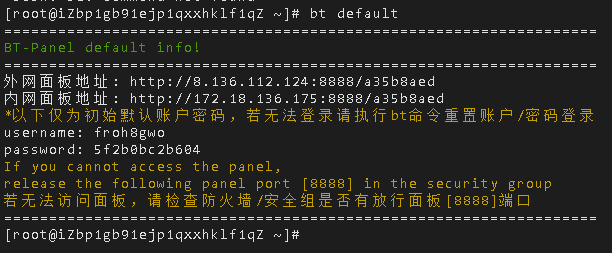
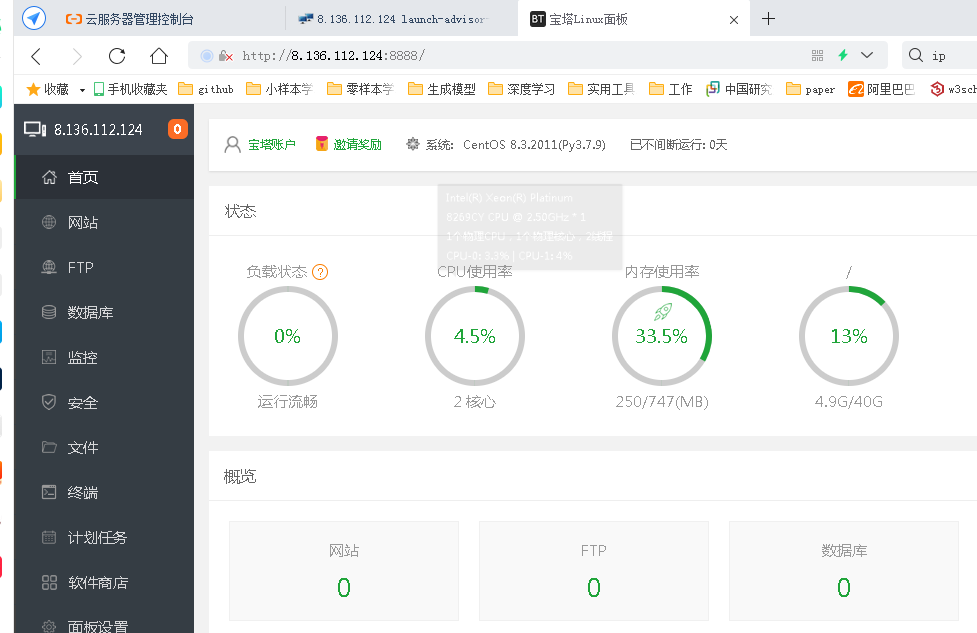
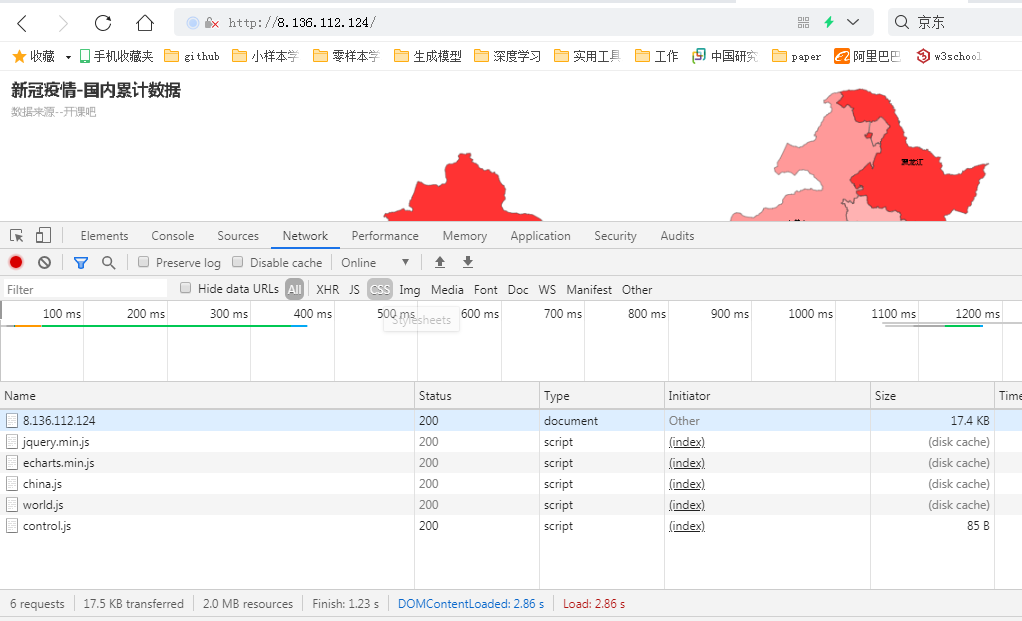
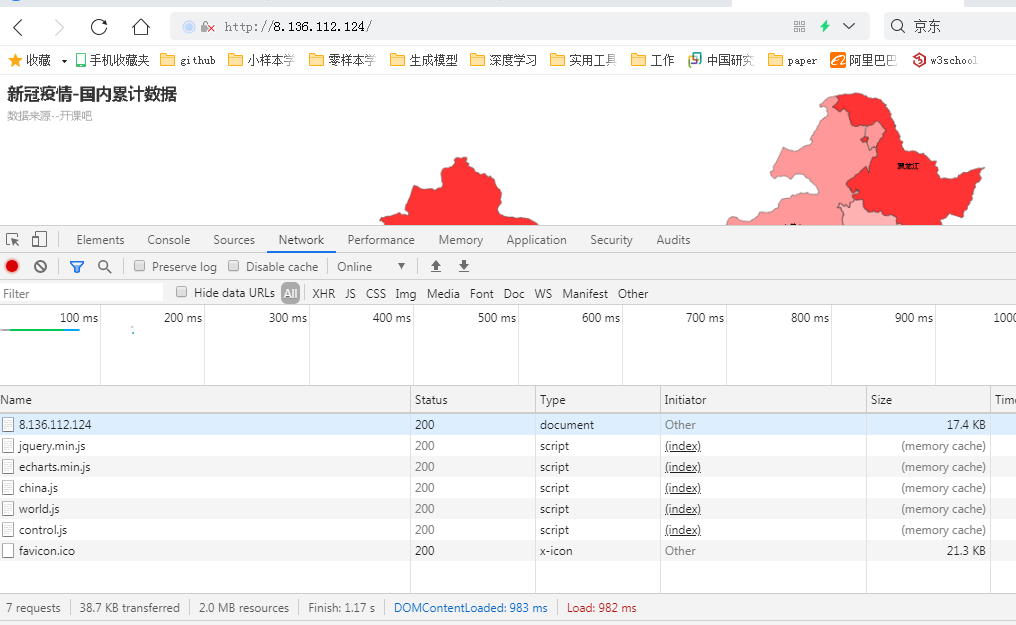
三、疫情地图部署上线
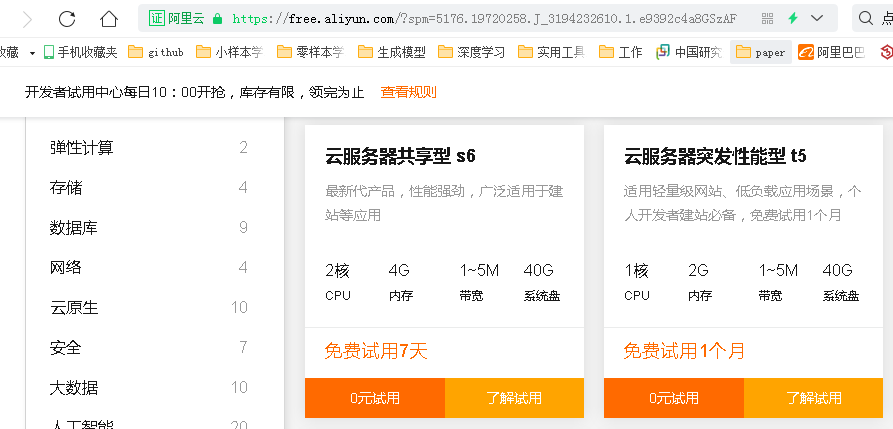
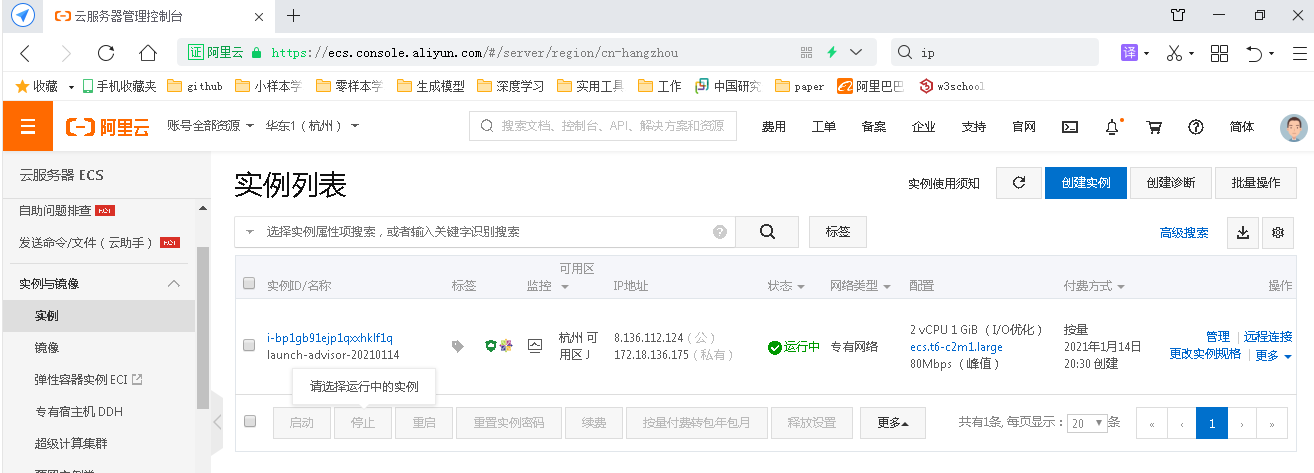
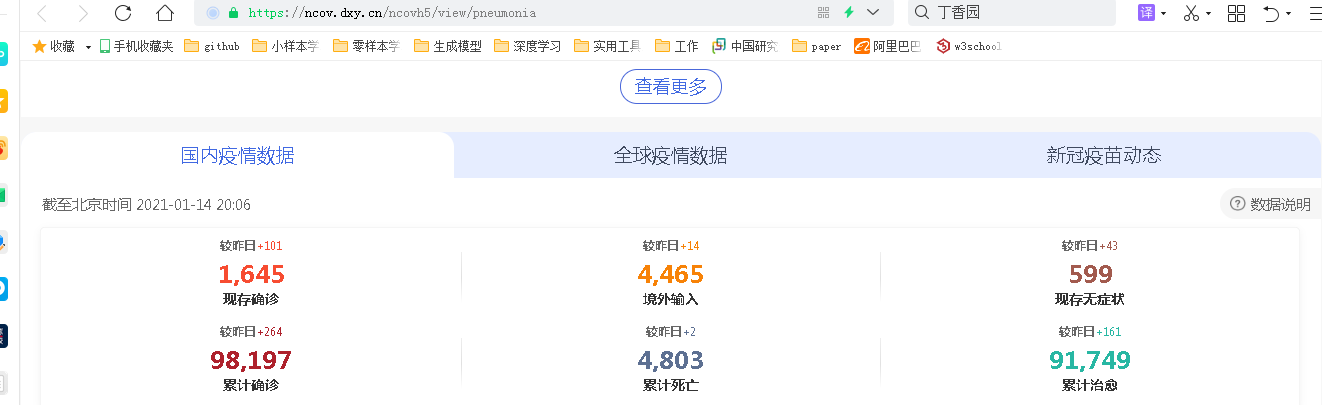
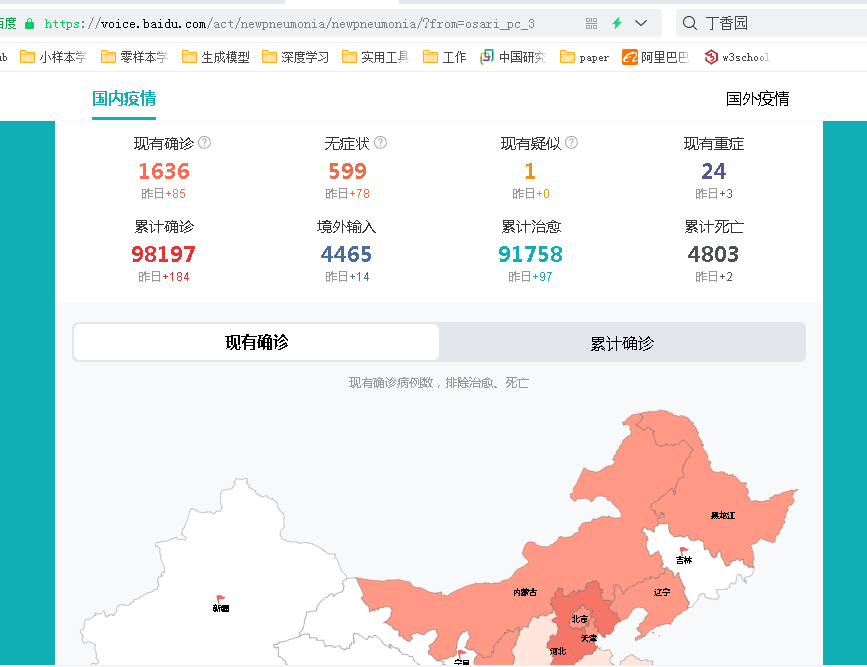
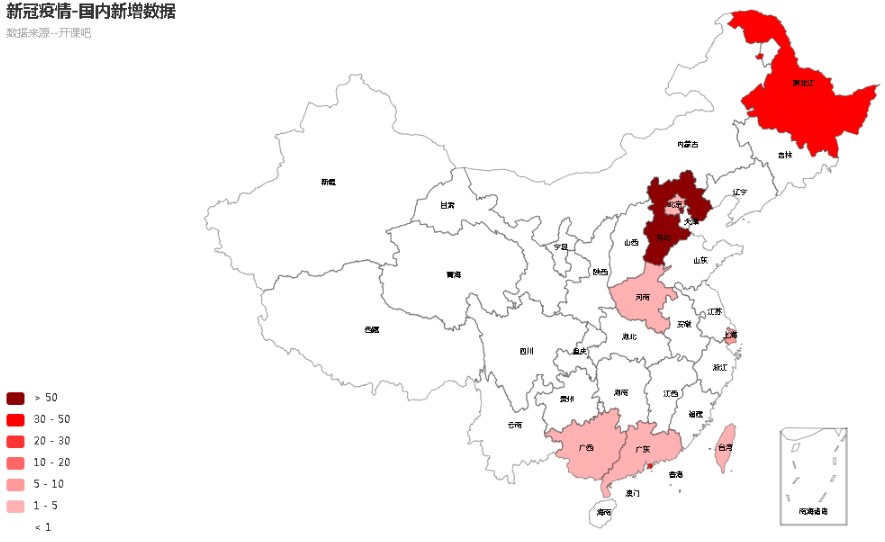
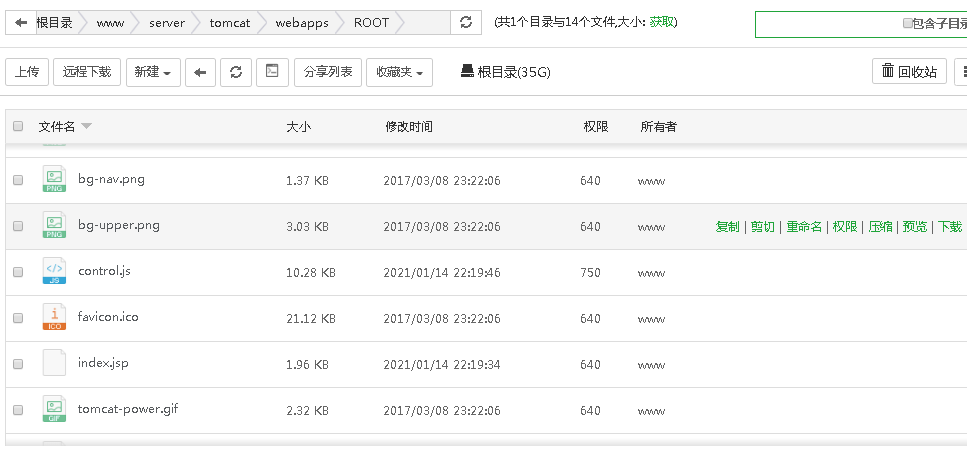
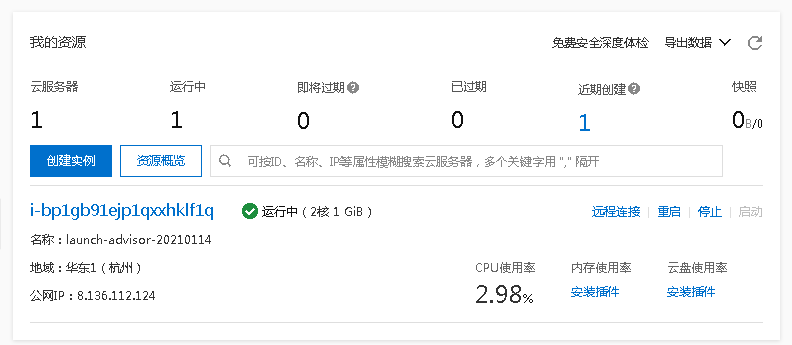
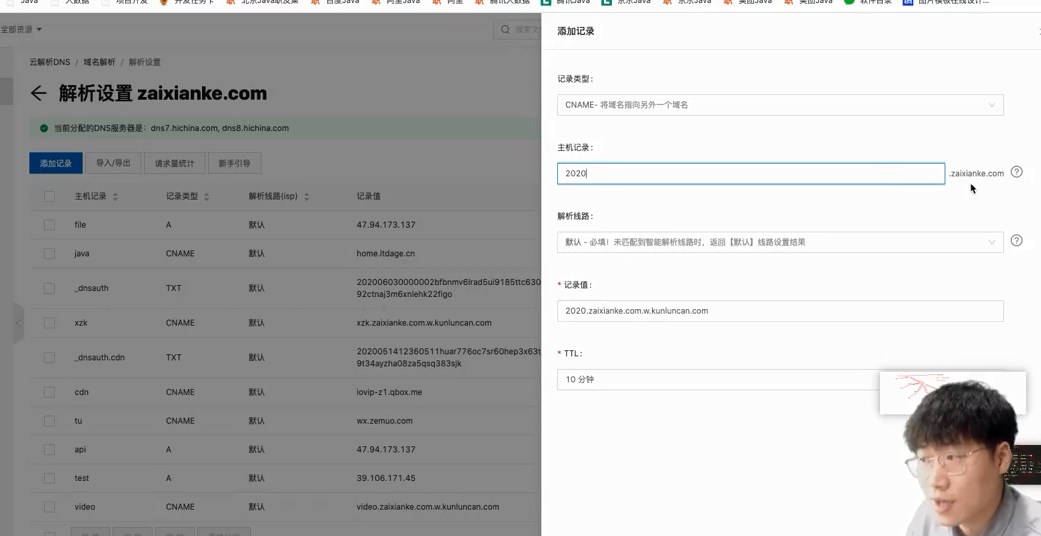
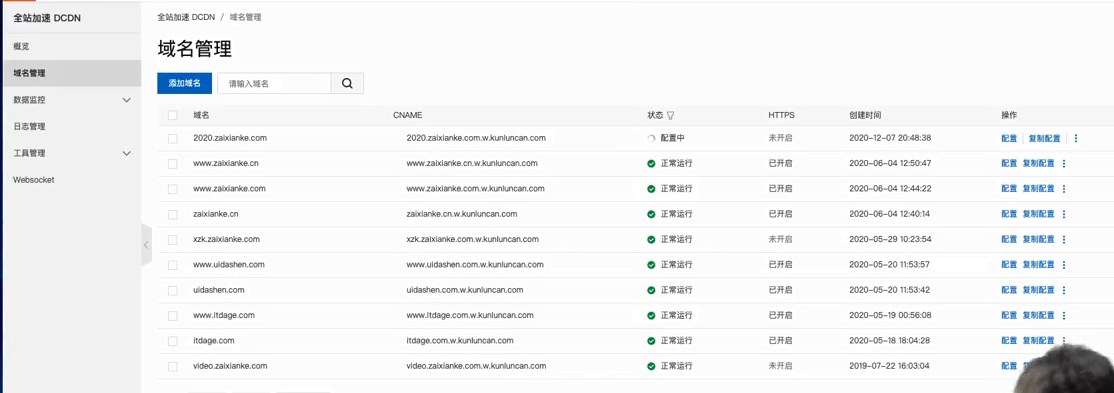
疫情数据分析、地图可视化、阿里云服务器搭建、校招30W+能力拆解 1、服务器搭建 https://free.aliyun.com/?spm=5176.19720258.J_3194232610.1.e9392c4a8GSzAF 自己购买 云服务器管理控制台:https://ecs.console.aliyun.com/#/server/region/cn-hangzhou?instanceIds=i-bp1gb91ejp1qxxhklf1q 配置规则 修改此文件则可以更改页面,ROOT中的index.jsp 丁香园(先-再数字,前后端分离)、百度、网易疫情地图 数据来自于zaixianke.com/yq/all <%@ page session="false" pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>
<%@ page import="java.net.URL" %>
<%@ page import="java.net.URLConnection" %>
<%@ page import="java.io.InputStream" %>
<%@ page import="java.io.InputStreamReader" %>
<%@ page import="java.io.BufferedReader" %>
<html>
<head>
<title>疫情地图,并上传文件,通过jsp读取
</title>
<script>
<%
//java代码执行区域:用户每次访问都会执行
//先准备一个网址(URL类的对象 u)
URL url = new URL("https://zaixianke.com/yq/all");
//响应码为500表示服务器端出现错误,原因:无法识别中文
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
br.close();
%>
var data = <%=text%>
</script>
</head>
<body></body>
</html>
<%@ page session="false" pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>
<%@ page import="java.net.URL" %>
<%@ page import="java.net.URLConnection" %>
<%@ page import="java.io.InputStream" %>
<%@ page import="java.io.InputStreamReader" %>
<%@ page import="java.io.BufferedReader" %>
<!DOCTYPE html>
<html lang="en">
<head>
<title>疫情地图,并上传文件,通过jsp读取
</title>
<script>
<%
//java代码执行区域:用户每次访问都会执行
//先准备一个网址(URL类的对象 u)
URL url = new URL("https://zaixianke.com/yq/all");
//响应码为500表示服务器端出现错误,原因:无法识别中文
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
String text = br.readLine();
//显示
System.out.println(text);
br.close();
%>
var data = <%=text%>
</script>
<title>疫情地图</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/echarts/4.7.0/echarts.min.js"></script>
<script src="http://cdn.zaixianke.com/china.js"></script>
<script src="http://cdn.zaixianke.com/world.js"></script>
</head>
<body>
<div id="main" style="width: 100%;height:600px;"></div> <br>
<div style="text-align:center">
<a style="color:#333" class="control" align="center" href="javascript:updateMap(0)">国内累计</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(1)">国内新增</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(2)">全球累计</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(3)">全球新增</a>
</div>
<script src="control.js"></script>
</body>
</html>
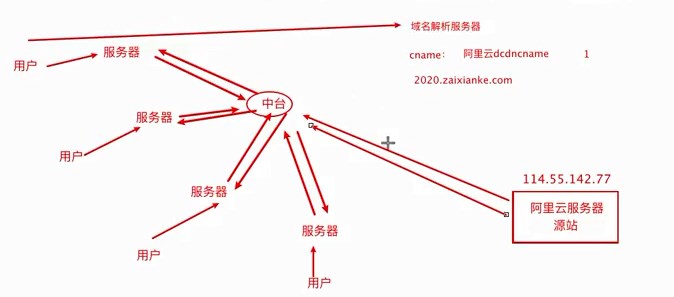
http://8.136.112.124/ 四、疫情地图优化
10倍并发优化、2800万的全球加速、千万级并发项目演进路线、高阶Java开发工程师快速成长之路 访问速度 使用缓存策略提高并发,通过nosql数据库如redis 通过一个数据,可以使用变量存储下来,查询时看数据是否够新(10分钟之内) <%@ page session="false" pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>
<%@ page import="java.net.URL" %>
<%@ page import="java.net.URLConnection" %>
<%@ page import="java.io.InputStream" %>
<%@ page import="java.io.InputStreamReader" %>
<%@ page import="java.io.BufferedReader" %>
<!DOCTYPE html>
<html lang="en">
<head>
<title>疫情地图,并上传文件,通过jsp读取
</title>
<script>
<%!
//java代码的声明区
//用来定义一些变量,只有用户第一次访问时会执行,后续访问重复使用第一次创建的变量
//时间戳:从格林威治历(1970年开始)开始到现在的13位毫秒数
//java中获取时间戳的方式:System.currentTimeMillis();
//用于缓存疫情数据的变量text
String text = null;//实现代码复用
//用于表示加载数据时的时间戳,0表示1970年
long time = 0;
%>
<%
//java代码执行区域:用户每次访问都会执行
if(System.currentTimeMillis() - time >600000){
//0.更新加载数据时的时间
time = System.currentTimeMillis();
//先准备一个网址(URL类的对象 u)
URL url = new URL("https://zaixianke.com/yq/all");
//响应码为500表示服务器端出现错误,原因:无法识别中文
//打开服务器连接,得到连接对象conn
java.net.URLConnection conn = url.openConnection();
//获取加载数据的字节输入流
InputStream is = conn.getInputStream();
//将is装饰为能一次读取一行的字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
//加载一行数据
text = br.readLine();
//显示
System.out.println(text);
br.close();
}
%>
var data = <%=text%>
</script>
<title>疫情地图</title>
<script src="https://cdn.bootcss.com/jquery/3.4.1/jquery.min.js"></script>
<script src="https://cdn.bootcss.com/echarts/4.7.0/echarts.min.js"></script>
<script src="http://cdn.zaixianke.com/china.js"></script>
<script src="http://cdn.zaixianke.com/world.js"></script>
</head>
<body>
<div id="main" style="width: 100%;height:600px;"></div> <br>
<div style="text-align:center">
<a style="color:#333" class="control" align="center" href="javascript:updateMap(0)">国内累计</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(1)">国内新增</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(2)">全球累计</a>
<a style="color:#333" class="control" align="center" href="javascript:updateMap(3)">全球新增</a>
</div>
<script src="control.js"></script>
</body>
</html>
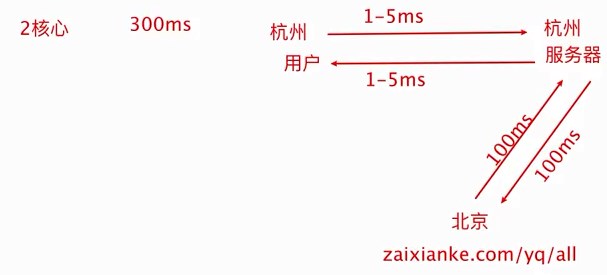
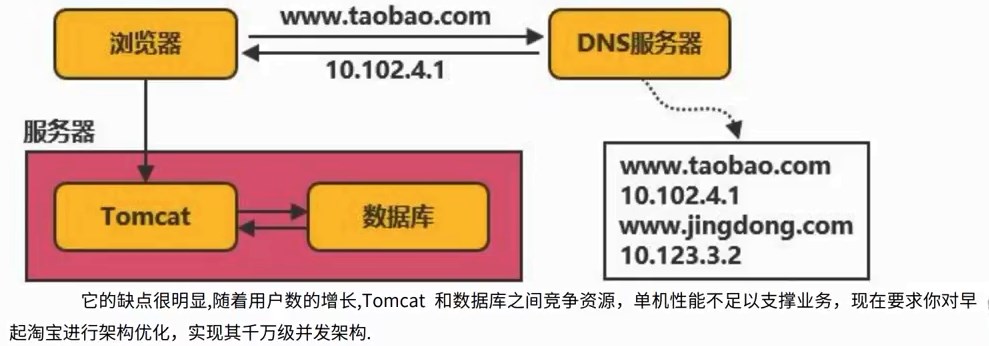
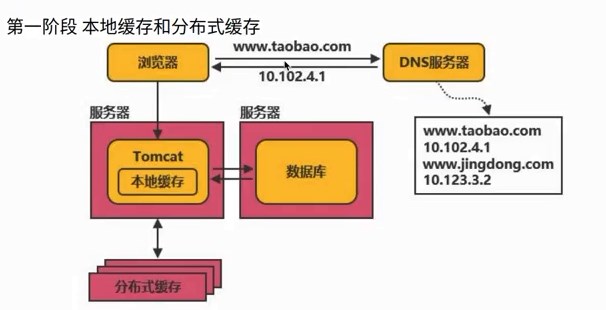
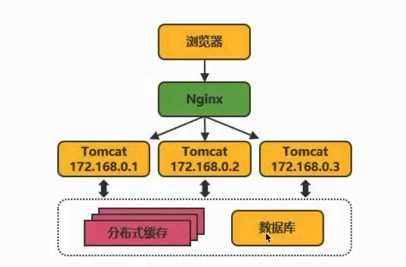
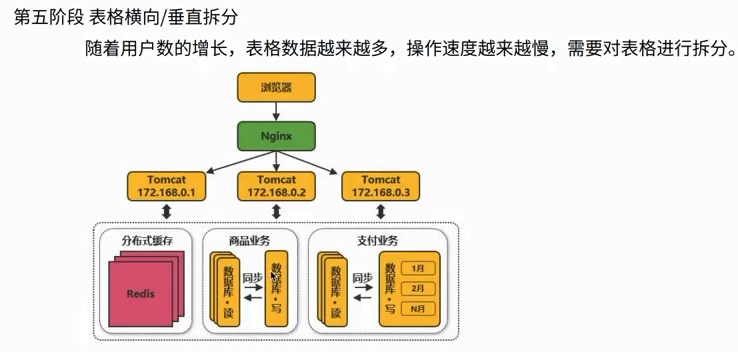
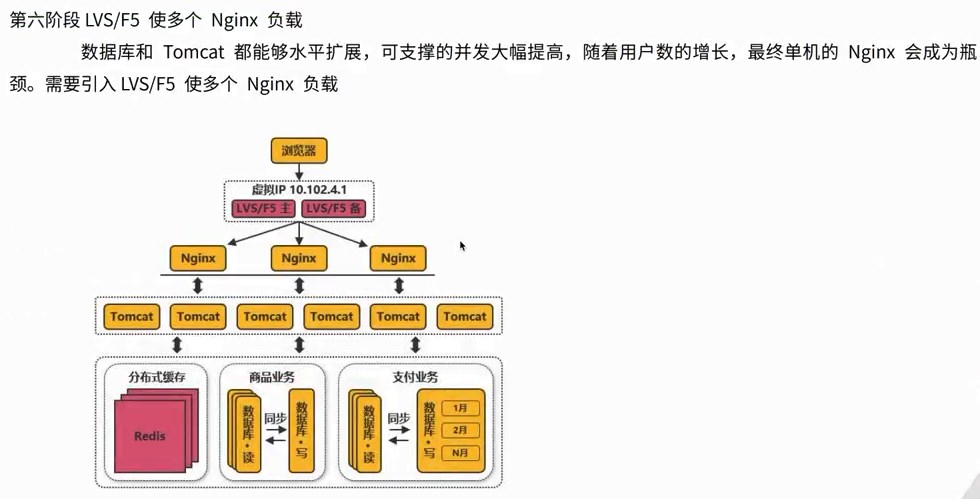
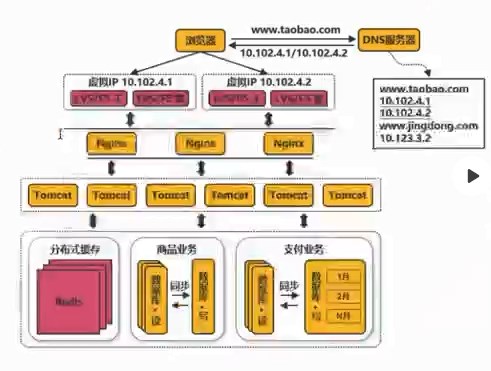
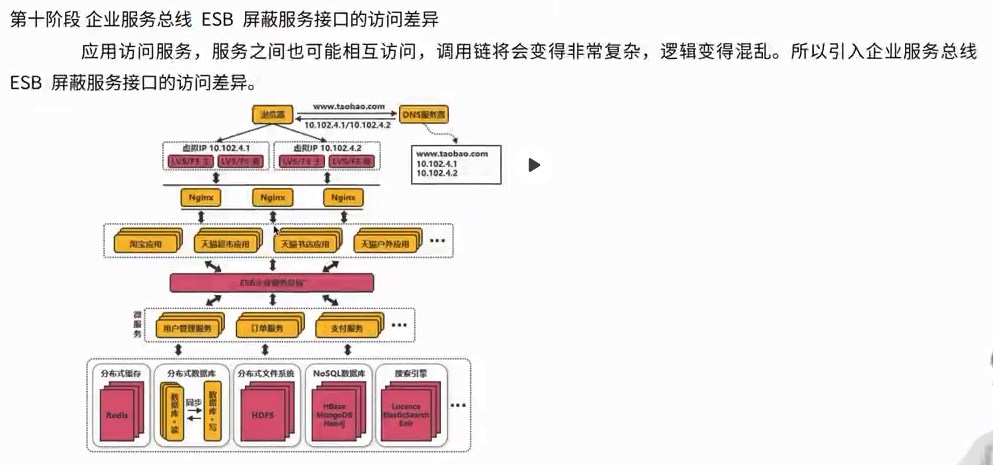
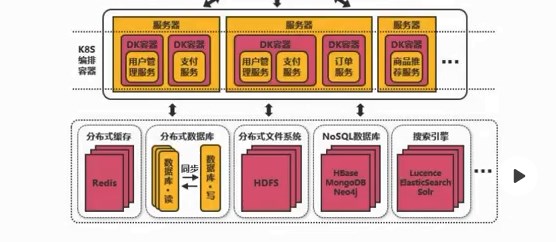
2、给项目加2800个全球节点的加速 查询:寻找距离近并且承载量足够的服务器(找快的服务器) 3、图示 各个城市的用户和服务器,通过中台服务器与不同位置的服务器连接进行统筹与沟通 源站点(访问疫情网站)的服务器:8.136.112.124 用户访问时,通过域名和域名解析服务器(设置cname)dcdncname找中台,通过中台从源站取服务器的数据,再将数据分发给服务器,用服务器进行解析 任务目标:掌握一款大型应用从百到千万级并发情况下服务端架构的演进过程(淘宝/京东/12306/拼多多等) 任务概述: 第二阶段:反向代理,通过Nginx,可以访问多个(3w)入口的tomcat 读的多,写的少,读对数据库的压力巨大,将数据库分为20份,15份读取,5份用于写数据 第四阶段:读的多,支付的就卡,用两个数据库,就没那么卡 第五阶段:查找几亿条订单,对订单以月/周为单位存 3W多的ip不够之后,引入虚拟ip技术 第六阶段:虚拟ip技术LVS/F5,一个机房的多个主机使用虚拟ip,多个Nginx,得到几十万个入口 横向扩展机房之后,很快被占满,后来发现是搜索业务耗费时间,大部分缓存数据,通过搜索引擎,可以将数据进行压缩 第九阶段:天猫和支付宝等的引入,同一个帐号,代码不再易于扩展和维护 将复用的代码拆分,抽离微服务,把共性的东西单独做服务(微服务),个性化的单独做,维护淘宝天猫不会崩 第十阶段:微服务抽取的,比如淘宝和天猫的支付流程是有差异的,实际上走的是一样的,通过企业服务总线,不再做差异化处理,更健壮
开始扩展机房费用较高,从而可以通过容器化技术节省成本
来自为知笔记(Wiz)
本文来自博客园,作者:哥们要飞,转载请注明原文链接:https://www.cnblogs.com/liujinhui/p/b0e7e2fc5cc2fb50304e31c3cb1f040e.html
来源:https://www.cnblogs.com/liujinhui/p/b0e7e2fc5cc2fb50304e31c3cb1f040e.html |


 發表於 2021-1-15 16:17:00
發表於 2021-1-15 16:17:00