前言部分
Hello-Agents 教程学习链接
github地址:https://github.com/datawhalechina/hello-agents
cookbook版本:https://book.heterocat.com.cn/
《Hello-agents》完整PDF免费下载
在学习之前:
✅ 具备基础Python编程能力、对大模型有一定概念
✅ 安装 Python 编程环境(Jupyter / PyCharm / VS Code){本文将使用Jupyter 作为基础环境}
✅ 具备基础MarkDown语法基础,完成每次学习笔记
特别感谢本教程各位开源贡献者及文睿的支持
认识智能体
2025 年被视为“Agent 元年”,多智能体协同(MAS)成为释放大模型潜能、解决真实复杂问题的关键。然而,网上我们可见的框架纷飞,能够进行系统学习的材料却非常稀缺,此次Hello-Agents 就可以作为链接初学者入门的桥梁,用第一性原理+实战,把开发者从“调 API 的用户”可自行模拟场景的创造者,带大家从零搭出属于自己的多智能体应用。简单来说,会聊天的大模型像装满知识的“大脑”,而 Agent 就是给大脑装上“手脚”和“团队”,让它能自己接单、查资料、写代码、互相讨论,把活干完。学 Agent 别急着追新框架,先弄懂“大脑怎么想、手脚怎么动、队员怎么配合”这三件事,再结合本教程中的一些小项目练手,一点点把流程跑通,即可食用(*╹▽╹*)。。。
什么是智能体?
智能体不是更会聊天的 GPT,而是一套“大模型驱动、具备自主经济学结构且没有感情的数字工人”
它最核心的专业组件有三件:
- 规划模块,通常用 ReAct、Chain-of-Thought 或树搜索算法把用户的一句话拆成可验证的子目标;
- 工具调用接口,通过 JSON Schema 或 OpenAI 的 parallel function call 把外部 API、数据库、Python 解释器封装成可执行动作空间(Action Space);
- 记忆与反思机制,利用向量数据库做语义检索,再用 Reflexion、Self-Critique 等提示策略让模型对自己的轨迹进行梯度无关的“元学习”。
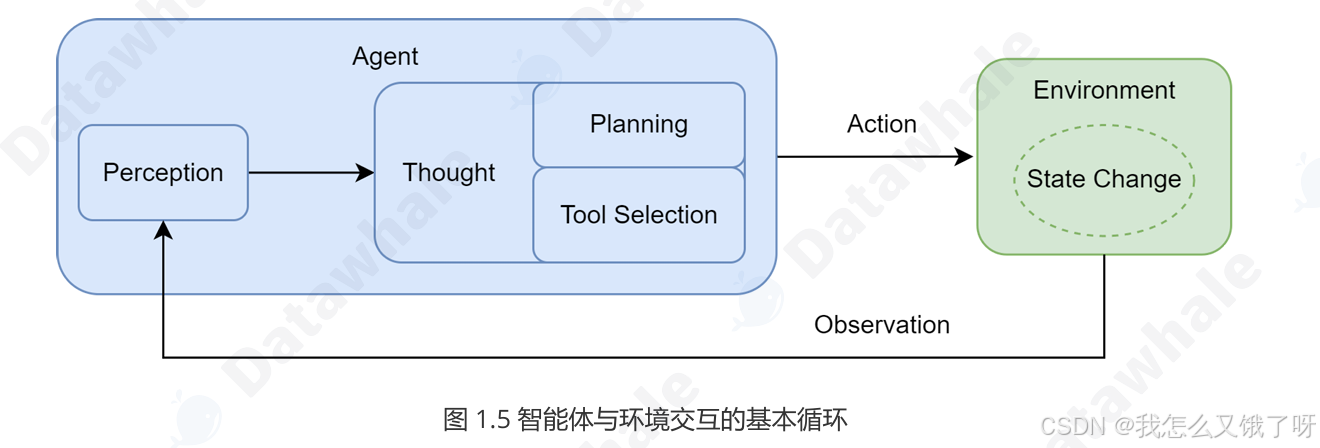
这三件套结束后,Agent 就不再只是“生成答案”,而是“生成动作序列”,在环境中观测(Observation)→ 推理(Reasoning)→ 行动(Action)→ 获得奖励(Reward),形成完整的 POMDP(部分可观察马尔可夫决策过程)回路(这里使用课件的图做以解释,简单来说就是
感知——思考——行动)
多智能体系统进一步把单点智能体升级为“数字组织”。每个 Agent 拥有角色画像(Persona)、私有记忆池(Private Memory)和通信协议(如 ACL、KQL、自然语言信道),通过共识算法(ReAct-Deliberation、LLM-Debate)或博弈策略(Shapley 分配、拍卖机制)完成分工、谈判、甚至互相审计。这就把 LLM 的“涌现”从 token 层提升到系统层——群体智能(Swarm Intelligence)出现,算力即产能。 {这里说的可能有点抽象,大家可以先忽略,不影响后续学习}
搭建自己的第一个智能体
安装必要的第三方库(包括requests、tavily-python、openai)
pip install requests tavily-python openai
以下是教程样例中的代码:
AGENT_SYSTEM_PROMPT = """
你是一个智能旅行助手。你的任务是分析用户的请求,并使用可用工具一步步地解决问题。
# 可用工具:
- `get_weather(city: str)`: 查询指定城市的实时天气。
- `get_attraction(city: str, weather: str)`: 根据城市和天气搜索推荐的旅游景点。
# 行动格式:
你的回答必须严格遵循以下格式。首先是你的思考过程,然后是你要执行的具体行动,每次回复只输出一对Thought-Action:
Thought: [这里是你的思考过程和下一步计划]
Action: [这里是你要调用的工具,格式为 function_name(arg_name="arg_value")]
# 任务完成:
当你收集到足够的信息,能够回答用户的最终问题时,你必须在`Action:`字段后使用 `finish(answer="...")` 来输出最终答案。
请开始吧!
"""
import requests
import json
def get_weather(city: str) -> str:
"""
通过调用 wttr.in API 查询真实的天气信息。
"""
# API端点,我们请求JSON格式的数据
url = f"https://wttr.in/{city}?format=j1"
try:
# 发起网络请求
response = requests.get(url)
# 检查响应状态码是否为200 (成功)
response.raise_for_status()
# 解析返回的JSON数据
data = response.json()
# 提取当前天气状况
current_condition = data['current_condition'][0]
weather_desc = current_condition['weatherDesc'][0]['value']
temp_c = current_condition['temp_C']
# 格式化成自然语言返回
return f"{city}当前天气:{weather_desc},气温{temp_c}摄氏度"
except requests.exceptions.RequestException as e:
# 处理网络错误
return f"错误:查询天气时遇到网络问题 - {e}"
except (KeyError, IndexError) as e:
# 处理数据解析错误
return f"错误:解析天气数据失败,可能是城市名称无效 - {e}"
import os
from tavily import TavilyClient
def get_attraction(city: str, weather: str) -> str:
"""
根据城市和天气,使用Tavily Search API搜索并返回优化后的景点推荐。
"""
# 从环境变量或主程序配置中获取API密钥
api_key = os.environ.get("TAVILY_API_KEY") # 推荐方式
# 或者,我们可以在主循环中传入,如此处代码所示
if not api_key:
return "错误:未配置TAVILY_API_KEY。"
# 2. 初始化Tavily客户端
tavily = TavilyClient(api_key=api_key)
# 3. 构造一个精确的查询
query = f"'{city}' 在'{weather}'天气下最值得去的旅游景点推荐及理由"
try:
# 4. 调用API,include_answer=True会返回一个综合性的回答
response = tavily.search(query=query, search_depth="basic", include_answer=True)
# 5. Tavily返回的结果已经非常干净,可以直接使用
# response['answer'] 是一个基于所有搜索结果的总结性回答
if response.get("answer"):
return response["answer"]
# 如果没有综合性回答,则格式化原始结果
formatted_results = []
for result in response.get("results", []):
formatted_results.append(f"- {result['title']}: {result['content']}")
if not formatted_results:
return "抱歉,没有找到相关的旅游景点推荐。"
return "根据搜索,为您找到以下信息:\n" + "\n".join(formatted_results)
except Exception as e:
return f"错误:执行Tavily搜索时出现问题 - {e}"
# 将所有工具函数放入一个字典,方便后续调用
available_tools = {
"get_weather": get_weather,
"get_attraction": get_attraction,
}
from openai import OpenAI
class OpenAICompatibleClient:
"""
一个用于调用任何兼容OpenAI接口的LLM服务的客户端。
"""
def __init__(self, model: str, api_key: str, base_url: str):
self.model = model
self.client = OpenAI(api_key=api_key, base_url=base_url)
def generate(self, prompt: str, system_prompt: str) -> str:
"""调用LLM API来生成回应。"""
print("正在调用大语言模型...")
try:
messages = [
{'role': 'system', 'content': system_prompt},
{'role': 'user', 'content': prompt}
]
response = self.client.chat.completions.create(
model=self.model,
messages=messages,
stream=False
)
answer = response.choices[0].message.content
print("大语言模型响应成功。")
return answer
except Exception as e:
print(f"调用LLM API时发生错误: {e}")
return "错误:调用语言模型服务时出错。"
import re
# --- 1. 配置LLM客户端 ---
# 请根据您使用的服务,将这里替换成对应的凭证和地址
API_KEY = "YOUR_API_KEY"
BASE_URL = "YOUR_BASE_URL"
MODEL_ID = "YOUR_MODEL_ID"
os.environ['TAVILY_API_KEY'] = "YOUR_TAVILY_API_KEY"
llm = OpenAICompatibleClient(
model=MODEL_ID,
api_key=API_KEY,
base_url=BASE_URL
)
# --- 2. 初始化 ---
user_prompt = "你好,请帮我查询一下今天北京的天气,然后根据天气推荐一个合适的旅游景点。"
prompt_history = [f"用户请求: {user_prompt}"]
print(f"用户输入: {user_prompt}\n" + "="*40)
# --- 3. 运行主循环 ---
for i in range(5): # 设置最大循环次数
print(f"--- 循环 {i+1} ---\n")
# 3.1. 构建Prompt
full_prompt = "\n".join(prompt_history)
# 3.2. 调用LLM进行思考
llm_output = llm.generate(full_prompt, system_prompt=AGENT_SYSTEM_PROMPT)
# 模型可能会输出多余的Thought-Action,需要截断
match = re.search(r'(Thought:.*?Action:.*?)(?=\n\s*(?:Thought:|Action:|Observation |\Z)', llm_output, re.DOTALL)
if match:
truncated = match.group(1).strip()
if truncated != llm_output.strip():
llm_output = truncated
print("已截断多余的 Thought-Action 对")
print(f"模型输出:\n{llm_output}\n")
prompt_history.append(llm_output)
# 3.3. 解析并执行行动
action_match = re.search(r"Action: (.*)", llm_output, re.DOTALL)
if not action_match:
print("解析错误:模型输出中未找到 Action。")
break
action_str = action_match.group(1).strip()
if action_str.startswith("finish"):
final_answer = re.search(r'finish\(answer="(.*)"\)', action_str).group(1)
print(f"任务完成,最终答案: {final_answer}")
break
tool_name = re.search(r"(\w+)\(", action_str).group(1)
args_str = re.search(r"\((.*)\)", action_str).group(1)
kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
if tool_name in available_tools:
observation = available_tools[tool_name](**kwargs)
else:
observation = f"错误:未定义的工具 '{tool_name}'"
# 3.4. 记录观察结果
observation_str = f"Observation: {observation}"
print(f"{observation_str}\n" + "="*40)
prompt_history.append(observation_str)
|\Z)', llm_output, re.DOTALL)
if match:
truncated = match.group(1).strip()
if truncated != llm_output.strip():
llm_output = truncated
print("已截断多余的 Thought-Action 对")
print(f"模型输出:\n{llm_output}\n")
prompt_history.append(llm_output)
# 3.3. 解析并执行行动
action_match = re.search(r"Action: (.*)", llm_output, re.DOTALL)
if not action_match:
print("解析错误:模型输出中未找到 Action。")
break
action_str = action_match.group(1).strip()
if action_str.startswith("finish"):
final_answer = re.search(r'finish\(answer="(.*)"\)', action_str).group(1)
print(f"任务完成,最终答案: {final_answer}")
break
tool_name = re.search(r"(\w+)\(", action_str).group(1)
args_str = re.search(r"\((.*)\)", action_str).group(1)
kwargs = dict(re.findall(r'(\w+)="([^"]*)"', args_str))
if tool_name in available_tools:
observation = available_tools[tool_name](**kwargs)
else:
observation = f"错误:未定义的工具 '{tool_name}'"
# 3.4. 记录观察结果
observation_str = f"Observation: {observation}"
print(f"{observation_str}\n" + "="*40)
prompt_history.append(observation_str)

自己第一次把 Agent 跑通时震撼是:
“原来我不是在调接口,而是在雇一个 24h 连轴转的初级算法工程师。”
给它一篇 arXiv 链接,它能自动拆 related work、跑实验、画曲线、写 README,还把 bug 清单发我邮箱。那一刻我深刻体会到,Agent 的真正杀伤力不在于“更像人”,而在于“把人最值钱的认知流水线封装成可复制的服务”。
当然,幻觉(Hallucination)、工具误调用(Tool Misuse)、目标漂移(Goal Drift)仍是技术壁垒0,根据以往的项目工程经验:
- 用“双塔”验证——让 Planner 与 Checker 两个独立模型互相对齐,降低级联错误;
- 把奖励函数拆成“硬规则 + 软语义”两层,硬规则用 Python assert 不可妥协,软语义用 cosine 相似度给 GPT-4 打分;
- 记忆分三级:热上下文(2k token)、温向量(24h 内)、冷归档(对象存储),既省成本又防上下文被“记忆淹没”。
Agent 是大模型从“概率生成器”走向“目标驱动的因果执行器”的桥梁,谁先能把这套“认知-动作”闭环低成本地跑通,谁就拥有下一个十年的自动化红利。
总结材料原文中写的很好,这里直接写入笔记:
- 智能体如何工作? 从基础上学习了智能体与环境交互的运行机制,这个持续的闭环是智能体处理 信息、做出决策、影响环境并根据反馈调整自身行为的基础。
- 如何构建智能体?以一个“智能旅行助手”为例,构建了一个完整的、由真实 LLM 驱 动的智能体。
课后习题
一、请分析以下四个 case 中的主体是否属于智能体,如果是,那么属于哪种类型的智能体(可以从多个分类维度进行分析),并说明理由:
case A :一台符合冯·诺依曼结构的超级计算机,拥有高达每秒 2EFlop 的峰值算力
case B :特斯拉自动驾驶系统在高速公路上行驶时,突然检测到前方有障碍物,需要在毫秒级做出刹车或变道决策
case C :AlphaGo在与人类棋手对弈时,需要评估当前局面并规划未来数十步的最优策略
case D :ChatGPT 扮演的智能客服在处理用户投诉时,需要查询订单信息、分析问题原因、提供解决方案并安抚用户情绪
A:纯硬件,无感知无目标 → 非智能体
B:车端感知-决策-控制闭环 → 物理实时智能体
C:自对弈深度规划 → 软件强化学习智能体
D:LLM+插件主动调用 → 工具增强对话智能体
Case A:2 EFlop 超级计算机
Case B:Tesla 自动驾驶高速避障
自主程度:高,毫米波+视觉+激光雷达实时感知,100 ms 内完成决策→转向/制动,无需人类接管
环境交互:强,输入连续交通场景,输出横纵向控制信号,直接影响车辆位姿
目标导向:明确——最小化碰撞概率+遵守交规+保持乘坐舒适
记忆与推理:短时记忆,但无长期策略学习
是智能体,类型:
按环境→物理智能体
按任务→实时反应型+ 部分规划型
按数量→单智能体
Case C:AlphaGo 对弈
Case D:ChatGPT 智能客服(带订单查询插件)
自主程度:高,给出投诉目标后,它能自主决定调用订单 API、生成回复、多次对话,无需人工逐句审核
环境交互:数字环境——通过插件读取订单数据库、知识库,再返回文本动作
目标导向:隐性——降低用户负面情感+提供可行方案,可用满意度作为奖励 proxy
记忆与推理:支持多轮上下文,可外挂向量记忆实现跨会话追溯
工具调用:显式调用 REST 函数,符合 ReAct 范式
是智能体,类型:
按环境→数字/信息智能体
按能力组合→工具增强语言智能体
按架构→单智能体,可扩展为多智能体
按交互方式→对话式智能体
二、假设你需要为一个"智能健身教练"设计任务环境。这个智能体能够通过可穿戴设备监测用户的心率、运动强度等生理数据根据用户的健身目标(减脂/增肌/提升耐力)动态调整训练计划在用户运动过程中提供实时语音指导和动作纠正评估训练效果并给出饮食建议请使用 PEAS 模型完整描述这个智能体的任务环境,并分析该环境具有哪些特性(如部分可观察、随机性、动态性等)。
环境特性分析
- 部分可观察,无法直接观测“真实疲劳度”“潜在关节损伤”“当日工作压力”,只能以 HR、HRV、表情、语音为带噪线索
- 随机性,同一训练强度下,次日 HR 恢复、肌肉酸痛、情绪状态均存在随机波动;传感器本身带白噪声
- 动态性,环境状态随时间持续变化:用户心率实时升降、血糖下降、地面突然湿滑、电话打断,Agent 必须持续重规划
- 连续性,心率、角度、力量曲线都是连续值;动作空间(阻力增减、语音速度)也是连续区间
- 序列性,当前动作是否标准会影响下一组能否执行、甚至影响数天后的受伤风险;奖励需考虑长期累积
- 多目标,需在“效果 vs 安全 vs 愉悦”之间做权衡,属于多目标决策
- 人机协作,一次训练约 60 min,可视为一段 episode;但整个健身周期 8-12 周,人可随时口头喊降低强度,Agent 必须在线响应
- 时空异构,用户体能随训练提升,同一强度刺激产生的效果递减,策略需定期微调


 發表於 2025-12-5 14:28:00
發表於 2025-12-5 14:28:00