|
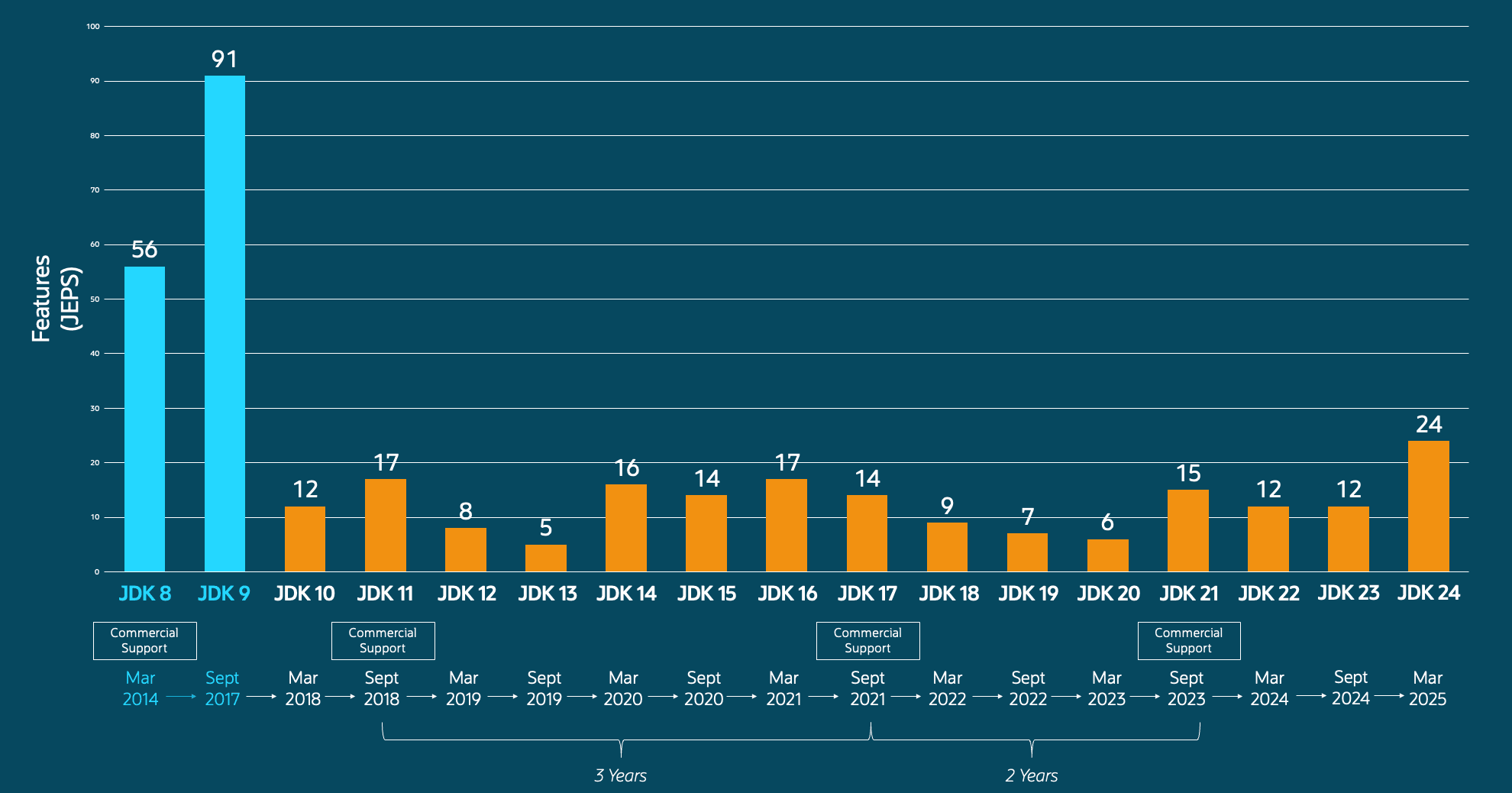
Java 8 终于要被淘汰了!
记得我从大一开始学的就是 Java 8,当时还叫做新特性;后来 Java 11 出了,我用 Java 8;Java 17 出了,我用 Java 8;Java 21 出了,我还用 Java 8。
随你怎么更新,我用 Java 8!
我之前带大家做项目的时候,还是强烈建议大家用 Java 8 的,为什么现在说 Java 8 要被淘汰了呢?
在我看来主要是因为业务和生态变了,尤其是这几年 AI 发展,很多老项目都要接入 AI、新项目直接面向 AI 开发,为了追求开发效率,我们要用 AI 开发框架(比如 Spring AI、LangChain4j),而这些框架要求的版本几乎都是 >= 17, 所以我们团队自己的业务也从 Java 8 迁到 Java 21 了。
另外也是因为有些新版本的 Java 特性确实很香,学会之后无论是开发效率还是性能都能提升一大截。
所以我做了本期干货内容,讲通 Java 8 ~ Java 24 的新特性,洋洋洒洒一万多字!建议收藏,看完后你就约等于学完了十几个 Java 版本~
⭐️ 推荐观看视频版,体验更佳:https://bilibili.com/video/BV1haamzUE8m
📚 免费 Java 教程 + 新特性大全:https://codefather.cn/course/java
⭐️ Java 8
Java 8 绝对是 Java 历史上最重要的稳定版本,也是这么多年来最受欢迎的 Java 版本,甚至有专门的书籍来讲解 Java 8。这个版本最大的变化就是引入了函数式编程的概念,给 Java 这门传统的面向对象语言增加了新的玩法。
【必备】Lambda 表达式
什么是 Lambda 表达式?
Lambda 表达式可以说是 Java 8 的杀手级特性。在这个特性出现之前,我们要实现一个简单的回调函数,只能通过匿名内部类的方式,代码又臭又长。
举些例子,比如给按钮添加点击事件、或者创建一个新线程执行操作,必须要自己 new 接口并且编写接口的定义和实现代码。
Lambda 表达式的出现,让代码变得简洁优雅,告别匿名内部类!
Lambda 表达式的语法非常灵活,可以根据参数个数和方法代码的复杂度选择不同的写法:
方法引用
Lambda 表达式还有一个实用特性叫做 方法引用,可以看作是 Lambda 表达式的一种简写形式。当 Lambda 表达式只是调用一个已存在的方法时,使用方法引用代码会更简洁。
举个例子:
List<String> names = Arrays.asList("鱼皮", "编程导航", "面试鸭");
实际开发中,方法引用经常用于获取某个 Java 对象的属性。比如使用 MyBatis Plus 来构造数据库查询条件时,经常会看到下面这种代码:
LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>();
lambdaQueryWrapper.eq(User::getName, "鱼皮");
方法引用有几种不同的形式,包括静态方法引用、实例方法引用、构造器引用,适用于不同的场景。
【必备】函数式接口
什么是函数式接口?
函数式接口是 只有一个抽象方法的接口。要玩转 Lambda 表达式,就必须了解函数式接口,因为 Lambda 表达式的本质是函数式接口的匿名实现。
展开来说,函数式接口定义了 Lambda 表达式的参数和返回值类型,而 Lambda 表达式提供了这个接口的具体实现。两者相辅相成,让 Java 函数式编程伟大!
常用的函数式接口
Java 8 为我们提供了很多内置的函数式接口,让函数式编程变得简单直观。列举一些常用的函数式接口:
1)Predicate 用于条件判断:
2)Function 接口用于数据转换,支持函数组合,让代码逻辑更清晰:
3)Consumer 和 Supplier 接口分别用于消费和提供数据:
4)BinaryOperator 接口用于二元操作,比如数学运算:
自定义函数式接口
虽然实际开发中,我们更多的是使用 Java 内置的函数式接口,但大家还是要了解一下自定义函数式接口的写法,有个印象。
使用自定义函数式接口,代码会更简洁:
💡 自定义函数式接口时,需要注意:
1)函数式接口必须是接口类型,不能是类、抽象类或枚举。
2)必须且只能包含一个抽象方法。否则 Lambda 表达式可能无法匹配接口。
3)建议使用 @FunctionalInterface注解。
虽然这个注解不是强制的,但加上后编译器会帮你检查是否符合函数式接口的规范(是否只有一个抽象方法),如果不符合会报错。
4)可以包含默认方法 default 和静态方法 static
函数式接口允许有多个默认方法和静态方法,因为它们不是抽象方法,不影响单一抽象方法的要求。
【必备】Stream API
什么是 Stream API?
Stream API 是 Java 8 另一个重量级特性,它让集合处理变得既优雅又高效。(学大数据的同学应该对它不陌生)
在 Stream API 出现之前,我们处理集合数据只能通过传统的循环,需要大量的样板代码。
比如过滤列表中的数据、将小写转为大写并排序:
List<String> words = Arrays.asList("apple", "banana", "cherry");
如果使用 Stream API,可以让同样的逻辑变得更简洁直观:
这就是 Stream 的作用。Stream 不是数据结构,而是 像工厂流水线 一样处理数据的工具。数据从一端进入,经历过滤、转换、排序等一系列加工步骤后,最终输出我们想要的结果。这种 链式调用 让代码读起来就像自然语言一样流畅。
Stream 操作类型
Stream 的操作分为中间操作和终端操作。中间操作是 “懒惰” 的,只有在遇到终端操作时才会真正执行。
filter 过滤和 map 映射都是中间操作,比如下面这段代码,并不会对列表进行过滤和转换:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
numbers.stream()
.filter(n -> n > 3)
一些常用的中间操作:
-
filter() - 过滤元素
-
map() - 转换元素
-
sorted() - 排序
-
distinct() - 去重
-
limit() - 限制数量
-
skip() - 跳过元素
给上面的代码加上一个终端操作 collect 后,才会真正执行:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
一些常用的终端操作:
-
collect() - 收集到集合
-
forEach() - 遍历每个元素
-
count() - 统计数量
-
findFirst() - 查找第一个
-
anyMatch() - 是否有匹配的
-
reduce() - 归约操作
实际应用
分享一些 Stream API 在开发中的典型用例。
1)对列表进行分组(List 转为 Map):
Map<Boolean, List<Integer>> partitioned = numbers.stream()
.filter(n -> n > 3)
2)使用 Stream 内置的统计功能,对数据进行统计:
3)按照对象的某个字段进行分组计算:
List<Person> people = Arrays.asList(
new Person("张三", 25, "北京"),
new Person("鱼皮", 18, "上海"),
new Person("李四", 25, "北京"),
new Person("老二", 35, "上海")
);
学过数据库的同学应该对这种操作并不陌生,其实 SQL 语句中的很多操作都可以通过 Stream 实现。这也是 Stream 的典型应用场景 —— 对数据库中查出的数据进行业务层面的运算。
并行流
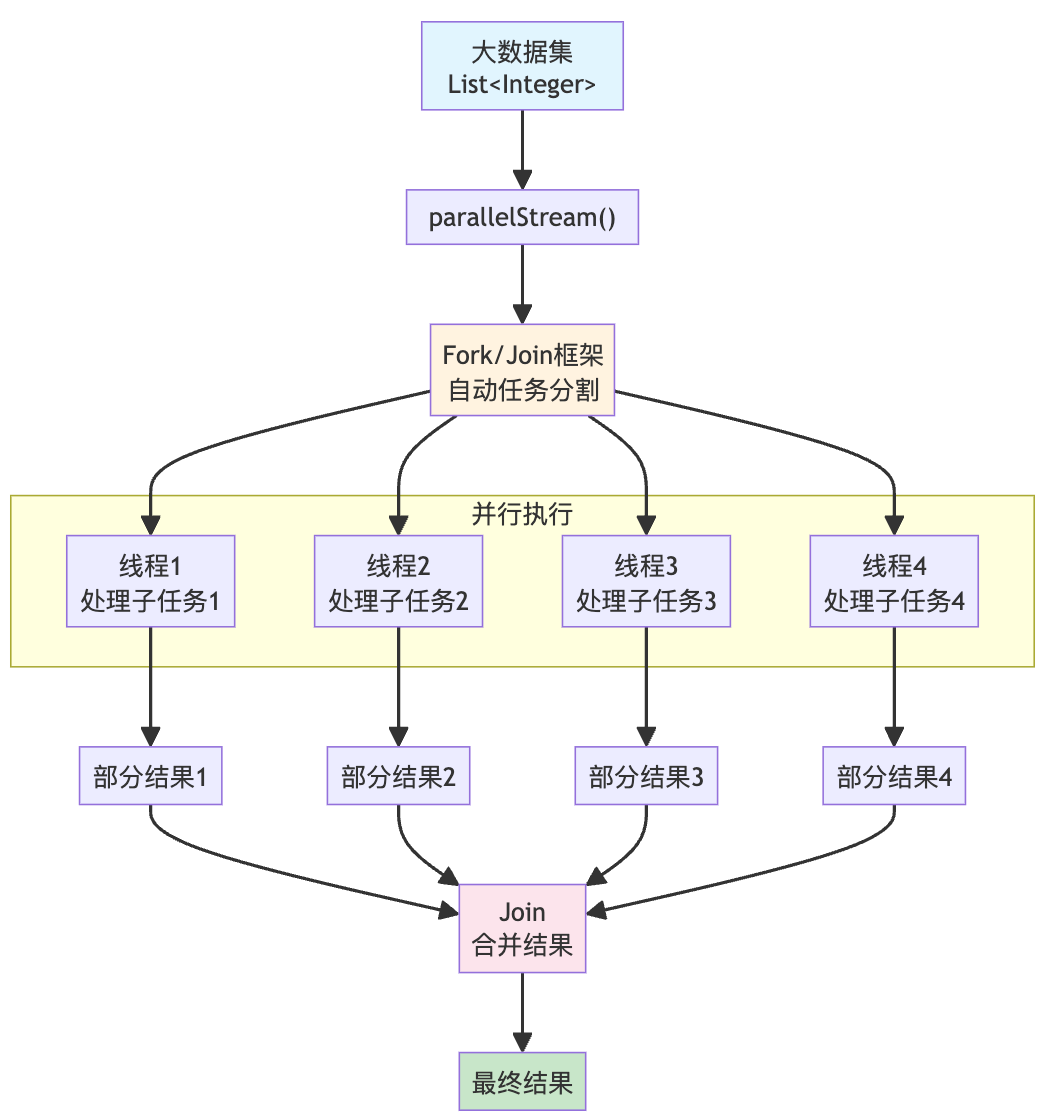
并行流是 Stream API 的另一个强大特性,它可以自动利用多核 CPU 处理器加速数据处理任务的执行。
在此之前,我们要实现并行处理集合数据,需要手动管理线程池和任务分割,代码复杂且容易出错。
但有了 Stream API,一行代码就能创建并行流,比如过滤并计算数据的总和:
List<Integer> largeList = IntStream.rangeClosed(1, 1000000)
.boxed()
.collect(Collectors.toList());
并行流底层使用了 Fork/Join 框架,简单来说就是把大任务拆分成小任务,分配给多个线程同时执行,最后把结果合并起来。这个过程对开发者完全透明,只需要调用 parallelStream() 即可。
但也正因如此,实际开发中,要谨慎使用并行流!
因为它使用的是 JVM 全局的 ForkJoinPool.commonPool(),默认线程数等于 CPU 核心数减 1。如果某个并行流任务阻塞了线程,会影响其他并行流的性能。
而且并行流不一定就更快,特别是对于简单操作或小数据集,切换线程的开销可能超过并行带来的收益。
因此,并行流更适合大数据量、CPU 密集型任务(如复杂计算、图像处理),不适合 I/O 密集型任务(如网络请求)。而且只要涉及到并发场景,就要考虑到线程安全问题。
【实用】Optional
Optional 的作用
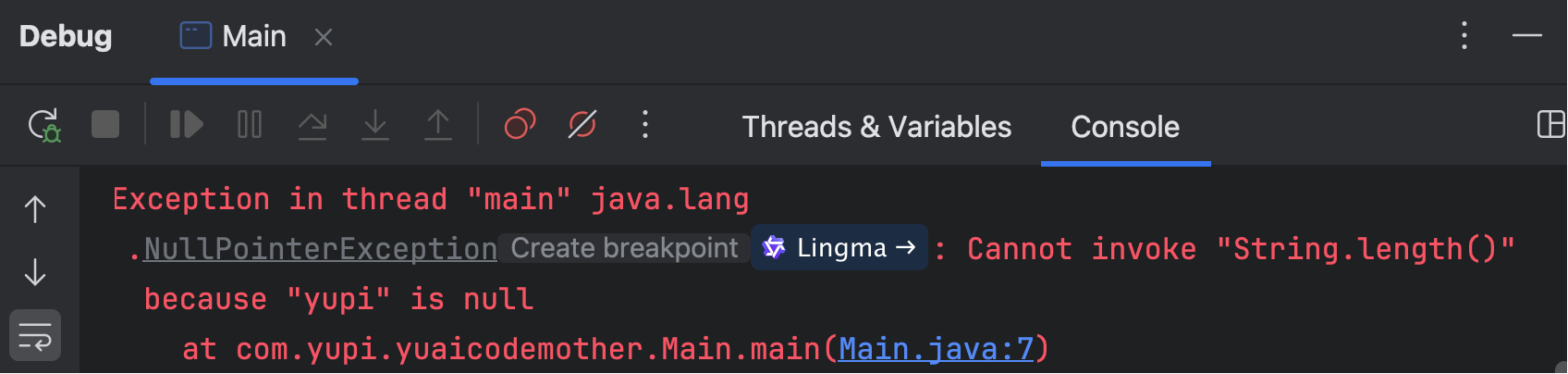
NullPointerException(NPE)一直是 Java 程序员的噩梦,学 Java 的同学应该都被它折磨过。
之前,我们只能通过大量的 if 语句检查 null 来避免空指针异常,不仅代码又臭又长,而且稍微不注意就漏掉了。
Optional 类的引入就是为了优雅地处理可能为空的值,可以先把它理解为 “包装器”,把可能为空的对象封装起来。
创建 Optional 对象:
Optional 提供了多种处理空值的方法:
还可以设置默认值策略,比如空值时抛出异常:
除了前面这些基本方法外,Optional 甚至提供了一套完整的 API 来处理空值场景!
跟 Stream API 类似,你可以对 Optional 封装的数据进行过滤、映射等操作:
optional
.filter(s -> s.length() > 5)
.map(String::toUpperCase)
.ifPresentOrElse(
System.out::println,
应用场景
鱼皮经常使用 Optional 来简化空值判断:
int pageNum = Optional.ofNullable(params.getPageNum())
.orElseThrow(() -> new RuntimeException("pageNum不能为空"));
如果不用 Optional,就要写下面这段代码:
int pageNum;
if (params.getPageNum() != null) {
pageNum = params.getPageNum();
} else {
throw new RuntimeException("pageNum不能为空");
}
此外,Optional 的一个典型应用场景是在集合中进行安全查找:
List<String> names = Arrays.asList("张三", null, "李四", "", "王五");
【必备】新的日期时间 API
Java 8 引入的新日期时间 API 解决了旧版 Date 和 Calendar 类的很多问题,比如线程安全、可变性、时区处理等等。
传统的日期处理方式:
使用新的日期时间 API,代码会更简洁:
典型的应用场景是从字符串解析日期,一行代码就能搞定:
还有日期和时间的计算,也变得更直观、见名知意:
LocalDate today = LocalDate.now();
还支持时区处理和时间戳处理,不过这段代码就没必要记了,现在有了 AI,直接让它生成时间日期操作就好。
总之,有了这套 API,我们不需要使用第三方的时间日期处理库,也能解决大多数问题。
【必备】接口默认方法
Java 8 引入的接口默认方法解决了接口演化的问题。
在默认方法出现之前,如果你想给一个被广泛使用的接口添加新方法,就会影响所有已有的实现类。想象一下,如果要给 Collection 接口添加一个新方法,ArrayList、LinkedList 等所有的实现类都需要修改,成本很大。
默认方法让接口可以在 不破坏现有代码的情况下添加新功能。
举个例子,如果想要给接口增加一个 drawWithBorder 方法:
public interface Drawable {
使用默认方法后,实现类可以选择重写默认方法,也可以直接使用:
Java 8 为 Collection 接口添加了 stream、removeIf 等方法,都是默认方法:
需要注意的是,如果一个类实现多个接口,并且这些接口有相同的默认方法时,需要显式解决冲突:
interface A {
default void hello() {
System.out.println("Hello from A");
}
}
interface B {
default void hello() {
System.out.println("Hello from B");
}
}
类似的,Java 8 还支持接口的静态方法,前面讲函数式接口的时候有提到。
Java 9
【了解】模块系统
在模块系统出现之前,传统 Java 应用只能依赖 classpath 来管理依赖,所有的类都在同一个类路径下,任何类都可以访问任何其他类,这种 “全局可见性” 在大型项目中会导致代码耦合严重、依赖关系混乱、运行时才发现 ClassNotFoundException 等问题。
模块系统允许我们将代码组织成模块,每个模块都有明确的依赖关系和导出接口,让大型应用的架构变得更加清晰和可维护。
模块系统通过 module-info.java 文件来定义模块的边界,明确声明哪些包对外开放,哪些依赖是必需的,这样就形成了强封装的架构。
比如一个用户管理模块只暴露用户服务接口,而内部的数据访问层对其他模块完全不可见,这种设计让系统的层次结构更加清晰,也避免了意外的跨层调用。
module user.management {
此外,模块系统还带来了更好的性能优化,JVM 可以在启动时只加载必需的模块,减少内存占用和启动时间(适合云原生应用)。
但是,模块系统在企业中用的比较少,目前大多数企业还是使用传统的 Maven/Gradle + JAR 包的方式管理依赖,改造项目的成本 > 模块系统带来的实际收益,所以仅作了解就好。
【了解】JShell 交互工具
JShell 是 Java 9 引入的一个交互式工具,在这个工具出现之前,我们要测试一小段 Java 代码,必须创建完整的类和 main 方法,编译后才能运行。
有了 JShell,我们可以像使用 Python 解释器一样使用 Java,对于学习调试有点儿用(但不多)。
直接在命令行输入 jshell 就能使用了:
【必备】集合工厂方法
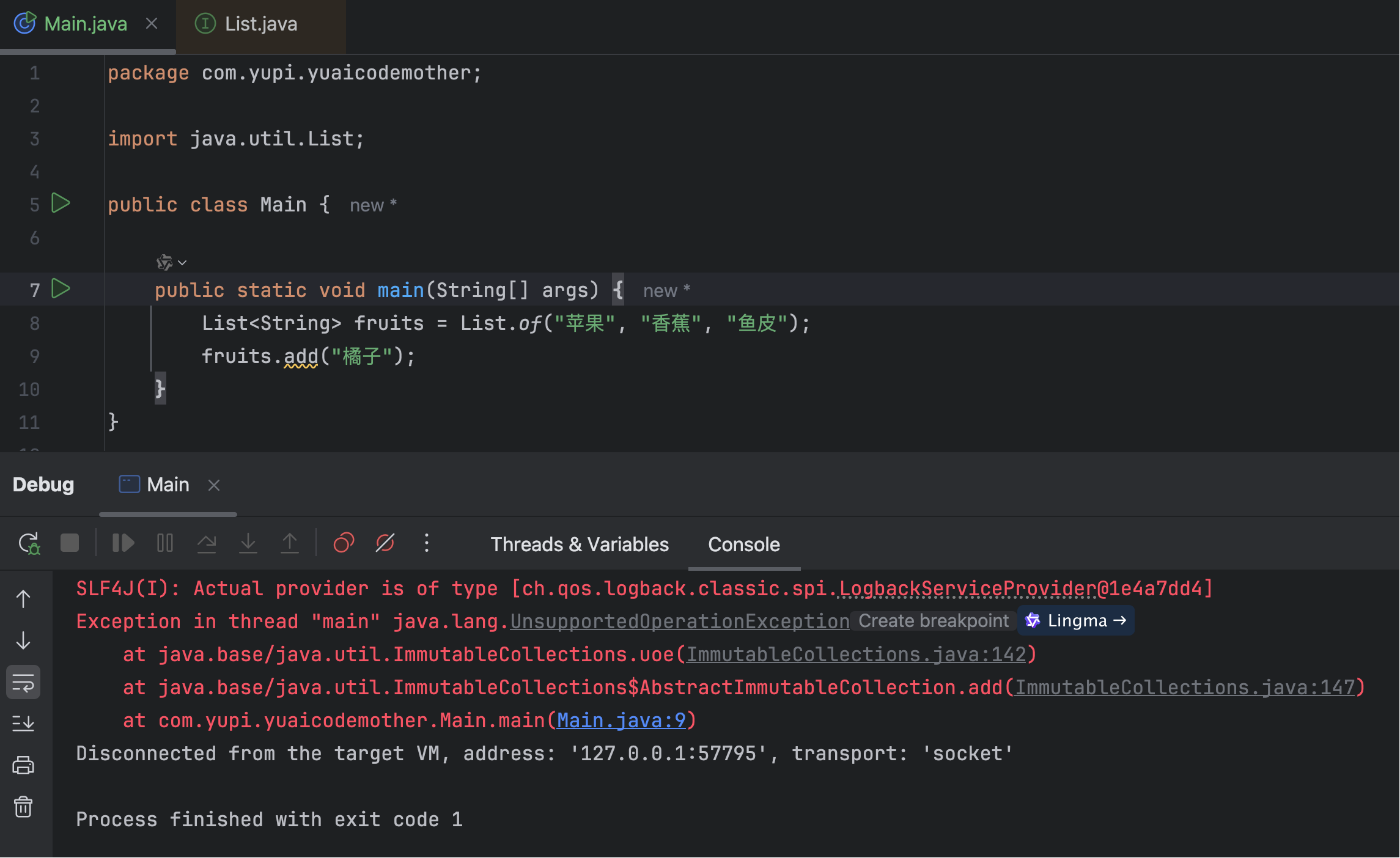
Java 9 为集合类添加了便捷的工厂方法,能够轻松创建不可变集合。
在这之前,创建不可变集合还是比较麻烦的,很多开发者会选择依赖第三方库(比如 Google Guava)。
传统的不可变集合创建方式:
有了 Java 9 的工厂方法,创建不可变集合简直不要太简单!
这些集合是真正不可变的,任何修改操作都会抛出 UnsupportedOperationException 异常。
如果想创建包含大量元素的不可变 Map,可以使用 ofEntries 方法:
Map<String, String> largeMap = Map.ofEntries(
Map.entry("key1", "value1"),
Map.entry("key2", "value2"),
Map.entry("key3", "value3")
【了解】接口私有方法
思考一个问题,如果某个接口中的默认方法需要复用代码,你会怎么做呢?
比如让你来优化下面这段代码:
public interface Calculator {
default double calculateRectangleArea(double width, double height) {
你会把重复的验证逻辑写在哪里呢?
答案很简单,写在一个外部工具类里,或者在接口内再写一个通用的验证方法:
public interface Calculator {
但这种方式存在一个问题,validate 作为 default 方法,它会成为接口的公共 API,所有实现类都能访问到!其实这个方法只需要在接口内可以使用就够了。
Java 9 解决了这个问题,允许在接口中定义私有方法(以及私有静态方法)。
public interface Calculator {
这样一来,接口内部可以优雅地复用代码,同时保持接口对外的简洁性。
💡 这里也能看出 Java 的演进很谨慎,先允许 default 方法(Java 8),再允许 private 方法(Java 9),每一步都有明确的设计考量。
【了解】改进的 try-with-resources
Java 9 改进了 try-with-resources 语句,在这之前,我们不能在 try 子句中使用外部定义的变量,必须在 try 括号内重新声明,会让代码变得冗余。
Java 9 的改进让代码更加简洁:
而且还可以同时使用多个变量:
public void processFiles(String file1, String file2) throws IOException {
var reader1 = Files.newBufferedReader(Paths.get(file1));
var reader2 = Files.newBufferedReader(Paths.get(file2));
try (reader1; reader2) {
Java 10
【实用】var 关键字
用过弱类型编程语言的朋友应该知道,不用自己声明变量的类型有多爽。
但是对于 Java 这种强类型语言,我们经常要写下面这种代码,一个变量类型写老长(特别是在泛型场景下):
Map<String, List<Integer>> complexMap = new HashMap<String, List<Integer>>();
ArrayList<String> list = new ArrayList<String>();
Iterator<Map.Entry<String, List<Integer>>> iterator = complexMap.entrySet().iterator();
好在 Java 10 引入了 var 关键字,支持局部变量的类型推断,编译器会根据初始化表达式自动推断变量的类型,让代码可以变得更简洁。
var complexMap = new HashMap<String, List<Integer>>();
var list = new ArrayList<String>();
var iterator = complexMap.entrySet().iterator();
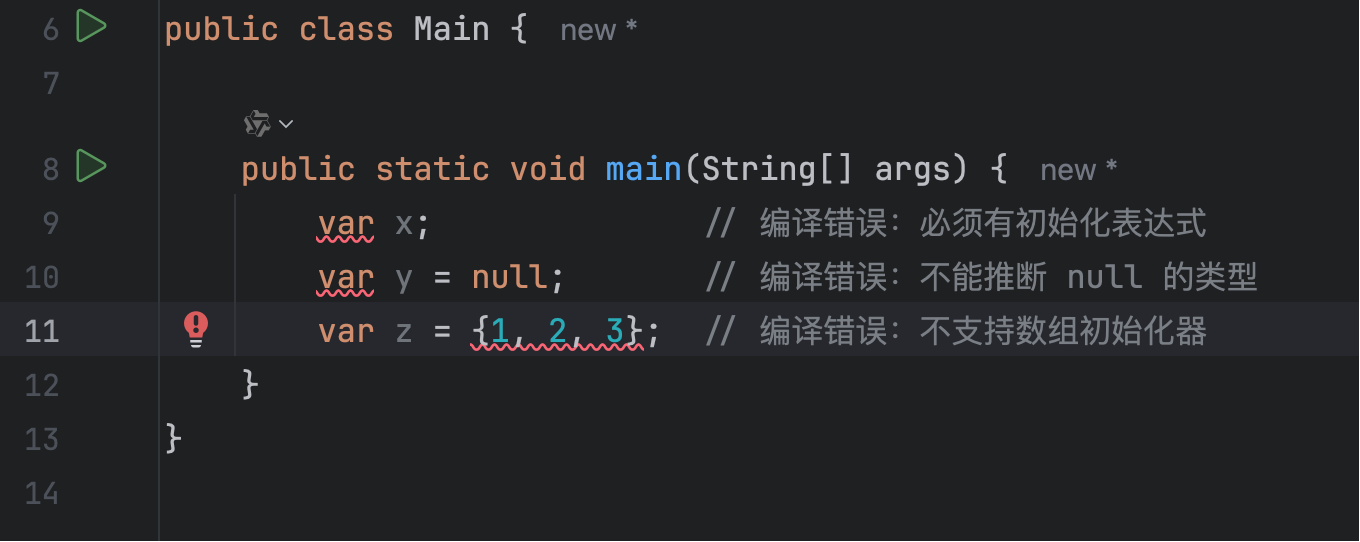
但是,var 关键字是一把双刃剑,不是所有程序员都喜欢它。毕竟代码中都是 var,丢失了一定的可读性,尤其是下面这种代码,你不能直观地了解变量的类型:
var data = getData();
而且使用 var 时,还要确保编译器能正确推断类型,下面这几种写法都是错误的:
所以我个人其实是没那么喜欢用这个关键字的,纯个人偏好。
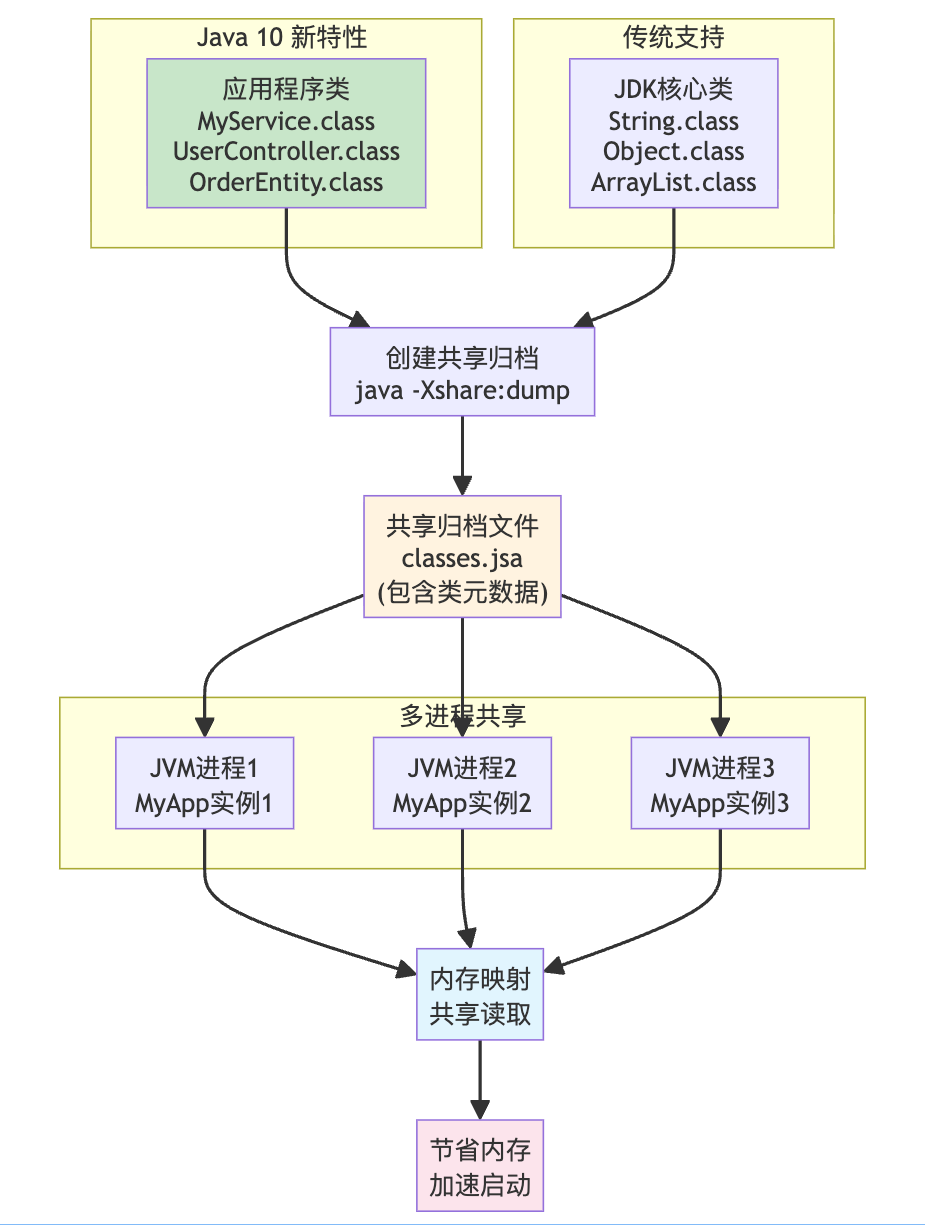
【了解】应用程序类数据共享
Java 10 扩展了类数据共享功能,允许应用程序类也参与共享(Application Class-Data Sharing)。在此之前,只有 JDK 核心类可以进行类数据共享,应用程序类每次启动都需要重新加载和解析。
类数据共享的核心思路是:将 JDK 核心类和应用程序类的元数据都打包到共享归档文件中,多个 JVM 实例同时映射同一个归档文件,通过 共享读取 优化应用启动时间和减少内存占用。
⭐️ Java 11
Java 11 是继 Java 8 之后的第二个 LTS 版本,这个版本的重点是提供更好的开发体验和更强大的标准库功能,特别是在字符串处理、文件操作和 HTTP 客户端方面,增加了不少新方法。
【实用】HTTP 客户端 API
HTTP 请求是后端开发常用的能力,之前我们只能基于内置的 HttpURLConnection 自己封装,或者使用 Apache HttpClient、OkHttp 第三方库。
还记得我第一次去公司实习的时候,就看到代码仓库内有很多老员工自己封装的 HTTP 请求代码,写法各异。。。
Java 11 将 HTTP 客户端 API 正式化,新的 HTTP 客户端提供了现代化的、支持 HTTP/2 和 WebSocket 的客户端实现,让网络编程变得简单。
支持发送同步和异步请求,能够轻松获取响应结果:
还支持自定义响应处理和 WebSocket 请求:
上面这些代码都不用记,现在直接把接口文档甩给 AI,让它来帮你生成请求代码就好。
【实用】String 类的新方法
Java 11 为 String 类添加了许多实用的方法,让字符串处理变得更加方便。
我估计很多现在学 Java 的同学都已经区分不出来哪些是新增的方法、哪些是老方法了,反正能用就行~
1)基本的字符串检查和处理:
String text = " Hello World \n\n";
String emptyText = " ";
String multiLine = "第一行\n第二行\n第三行";
2)strip() 系列方法
相比传统的 trim() 更加强大,能够处理 Unicode 空白字符:
3)lines() 方法,让多行字符串处理更简单:
4)repeat() 方法,可以重复字符串:
System.out.println("Java ".repeat(3));
即便如此,我还是更喜欢使用 Hutool 或者 Apache Commons 提供的字符串工具类。
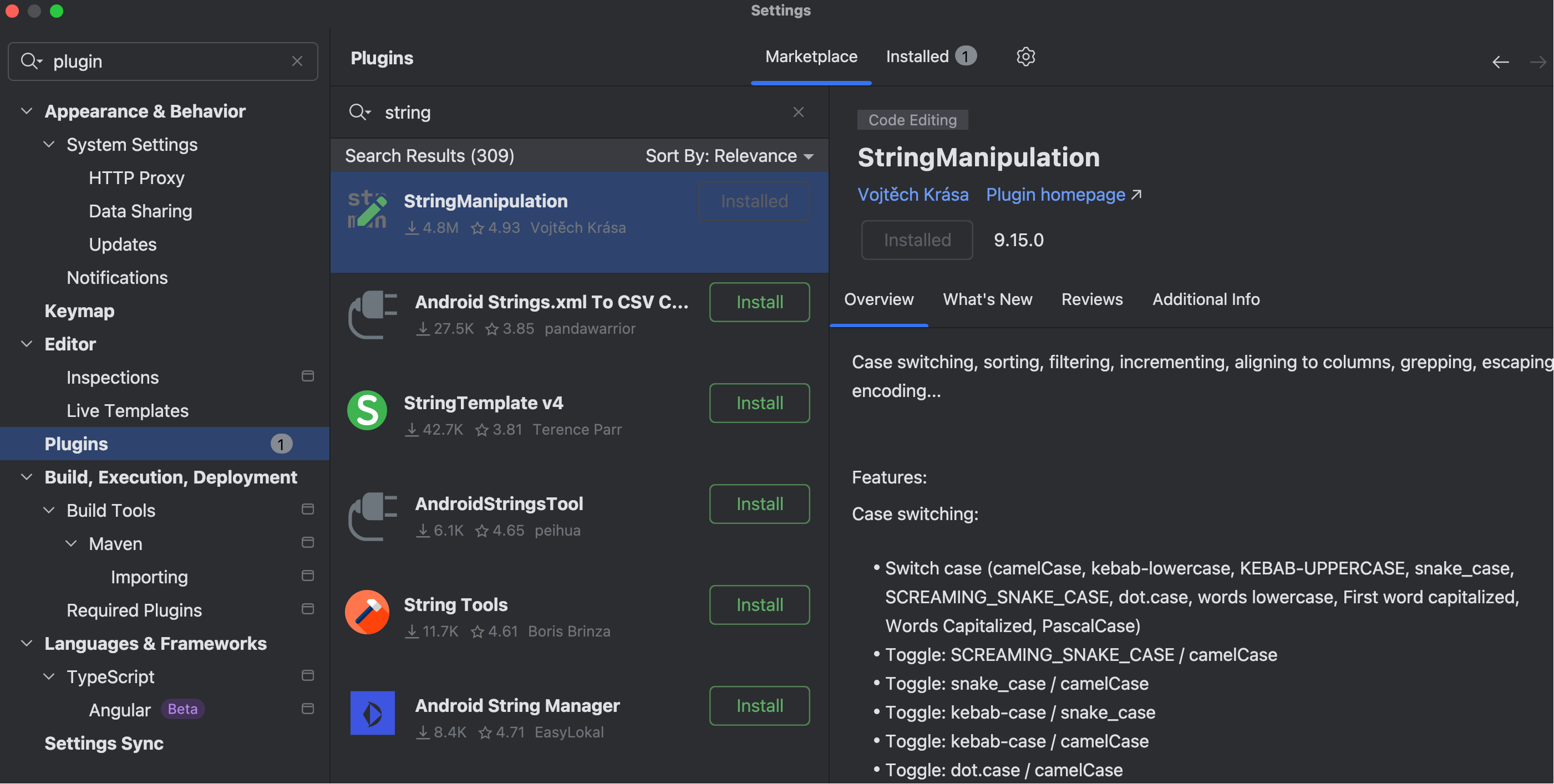
💡 提到字符串处理,鱼皮建议大家安装 StringManipulation 插件,便于我们开发时对字符串进行各种转换(比如小写转为驼峰):
【实用】Files 类的新方法
Java 11 为文件操作新增了更便捷的方法,不需要使用 FileReader / FileWriter 这种复杂的操作了。
基本的文件读写操作,一个方法搞定:
支持流式读取文件,适合文件较大的场景:
try (Stream<String> lines = Files.lines(tempFile)) {
lines.filter(line -> !line.isBlank())
.map(String::trim)
.forEach(System.out::println);
}
【了解】Optional 的新方法
Java 11 为 Optional 类添加了 isEmpty() 方法,和之前的 isPresent 正好相反,让空值检查更直观。
Java 12 ~ 13
Java 12 和 13 主要引入了一些预览特性,其中最重要的是 Switch 表达式和文本块,这些特性在后续版本中得到了完善和正式化。
Java 14
Java 14 将 Switch 表达式正式化,并引入了 Records、instanceof 模式匹配作为预览特性。
【必备】Switch 表达式
Java 14 将 Switch 表达式转正了,让条件判断变得更简洁和安全。
在这之前,传统的 switch 语句存在不少问题,比如需要手动添加 break 防止穿透、赋值不方便等:
String dayType;
switch (day) {
case MONDAY:
case TUESDAY:
case WEDNESDAY:
case THURSDAY:
case FRIDAY:
dayType = "工作日";
break;
case SATURDAY:
case SUNDAY:
dayType = "周末";
break;
default:
dayType = "未知";
break;
}
在 Java 14 之后,可以直接这么写:
上述代码中,我们使用了 Switch 表达式增强的几个特性:
-
箭头语法:使用 -> 替代冒号,自动防止 fall-through(不用写 break 了)
-
多标签支持:case A, B, C -> 一行处理多个条件
-
表达式求值:可以直接使用 yield 关键字返回值并赋给变量
这样一来,多条件判断变得更优雅了!还能避免忘记 break 导致的逻辑错误。
【了解】有用的空指针异常
Java 14 改进了 NullPointerException 的错误信息。JVM 会提供更详细的堆栈跟踪信息,指出导致异常的具体位置和原因,让调试变得更加容易。
Java 15
Java 15 将文本块正式化,新增了 Hidden 隐藏类,并引入了 Sealed 类作为预览特性。
【必备】文本块
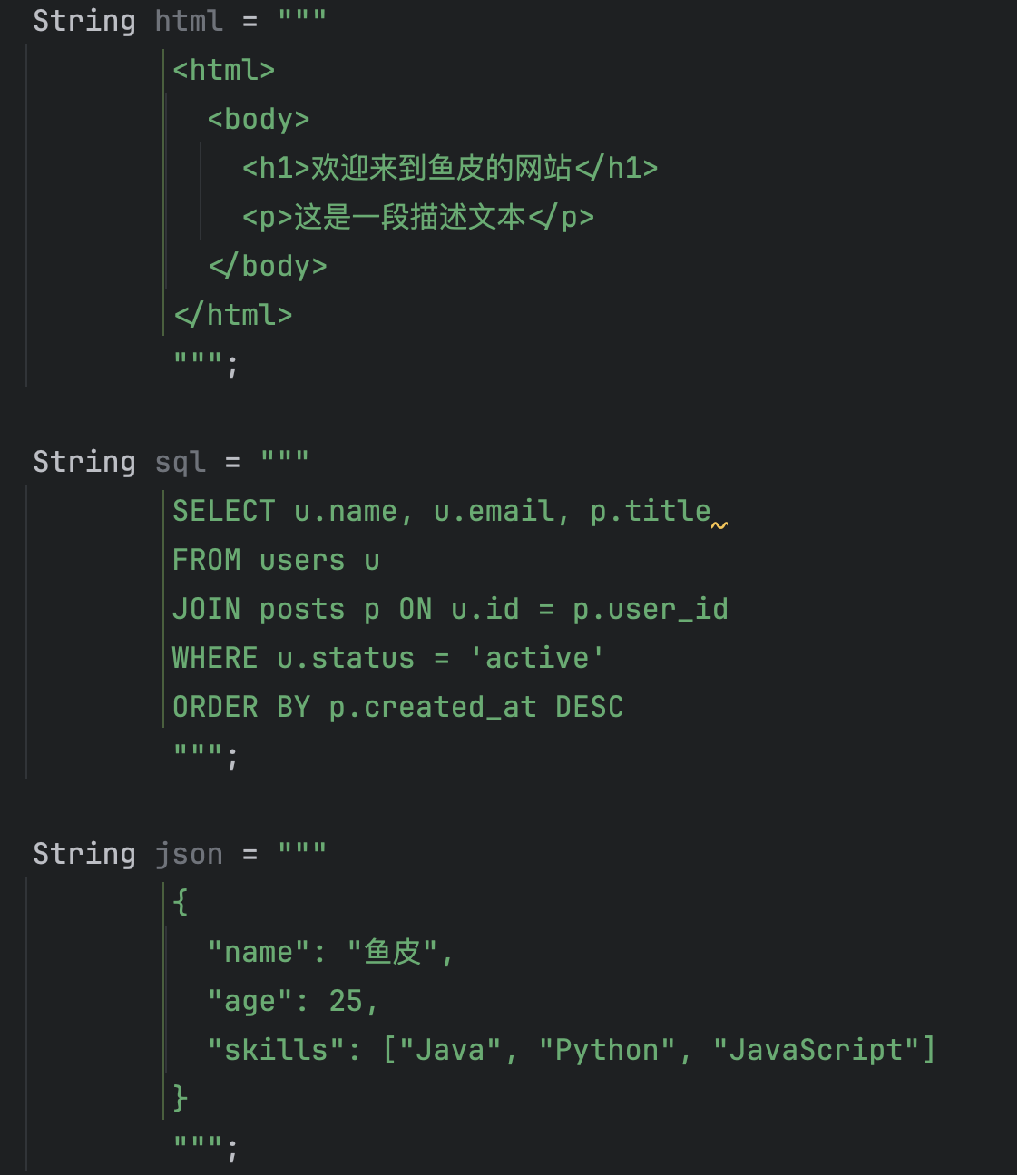
这可能是我最喜欢的特性之一了,因为之前每次复制多行文本到代码中,都会给我转成这么一坨:
需要大量的字符串拼接、转义字符,对于 HTML、SQL 和 JSON 格式来说简直是噩梦了。
有了 Java 15 的文本块特性,多行字符串简直不要太爽!直接用三个引号 """ 括起来,就能以字符串本来的格式展示。
文本块会保持代码的缩进、而且内部的引号不需要转义。
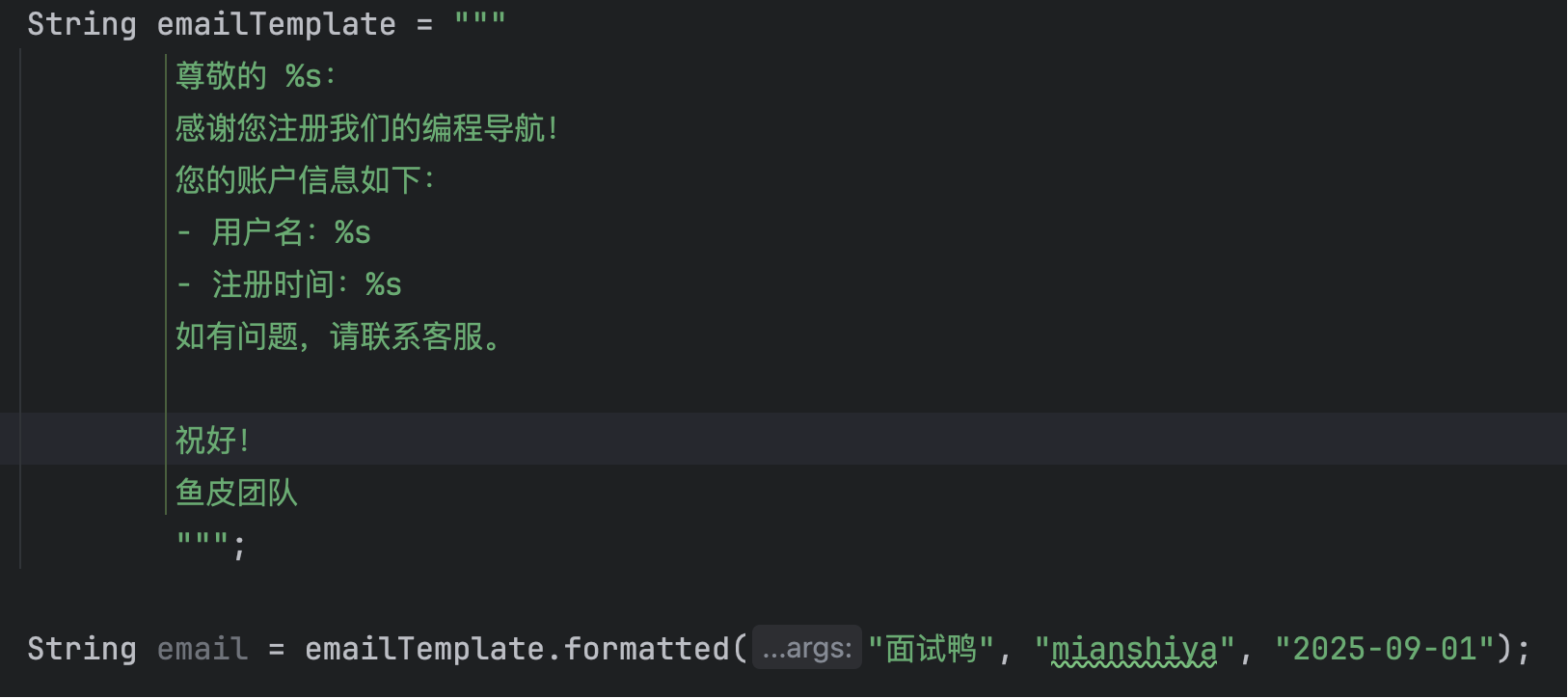
配合 String 的格式化方法,就能轻松传入参数生成复杂的字符串模板:
【了解】Hidden 隐藏类
Java 15 引入了 Hidden 隐藏类特性,这是一个 专为框架和运行时环境设计 的底层机制,主要是为了优化 动态生成短期类(比如 Lambda 表达式、动态代理)的性能问题,普通开发者无需关心。
在 Lambda 表达式、AOP 动态代理、ORM 映射等场景中,框架会动态生成代码载体(比如方法句柄、临时代理类),这些载体需要关联类的元数据才能运行。如果生成频繁,传统类的元数据会被类加载器追踪,需要等待类加载器卸载才能回收,导致元空间堆积和 GC 压力。
Hidden 类的特点是对其定义类加载器之外的所有代码都不可见,由于不可发现且链接微弱,JVM 垃圾回收器能够更高效地卸载隐藏类及其元数据,从而防止短期类堆积对元空间造成压力,优化了需要动态生成大量类的性能。
Java 16
Java 16 正式发布了 Records 和 instanceof 模式匹配这 2 大特性,让代码更简洁易读。
【必备】Records
以前,我们如果想创建一个 POJO 对象来存一些数据,需要编写大量的样板代码,包括构造函数、getter 方法、equals、hashCode 等等,比较麻烦。
即使通过 Lombok 插件简化了代码,估计也要十几行。
有了 Java 16 的 Records,创建数据包装类简直不要太简单,一行代码搞定:
public record Person(String name, int age, String email) {}
Records 自动提供了所有必需的方法,使用方式完全一样!
Person person = new Person("鱼皮", 25, "yupi@yuyuanweb.com");
System.out.println(person.name());
此外,Records 还支持自定义方法和验证逻辑,只不过个人建议这种情况下不如老老实实用 “类” 了。
public record BankAccount(String accountNumber, double balance) {
【了解】instanceof 模式匹配
Java 16 正式推出了 instanceof 的模式匹配,让类型检查和转换变得更优雅。
传统的 instanceof 使用方式,需要显示转换对象类型:
Object obj = xxx;
if (obj instanceof String) {
String str = (String) obj;
有了 instanceof 模式匹配,可以直接在匹配类型时声明变量:
if (obj instanceof String str) {
return "字符串长度: " + str.length();
}
但是要注意,str 变量的作用域被限定在 if 条件为 true 的代码块中,符合最小作用域原则。
【了解】Stream 新增方法
Java 16 为 Stream API 添加了 toList() 方法,可以用更简洁的代码将流转换为不可变列表。
还提供了 mapMulti() 方法,跟 flatMap 的作用一样,将一个元素映射为 0 个或多个元素,但是某些场景下比 flatMap 更灵活高效。
当需要从一个元素生成多个元素时,flatMap 需要先创建一个中间 Stream,而 mapMulti() 可以通过传入的 Consumer 直接 “推送” 多个元素,避免了中间集合或 Stream 的创建开销。
⭐️ Java 17
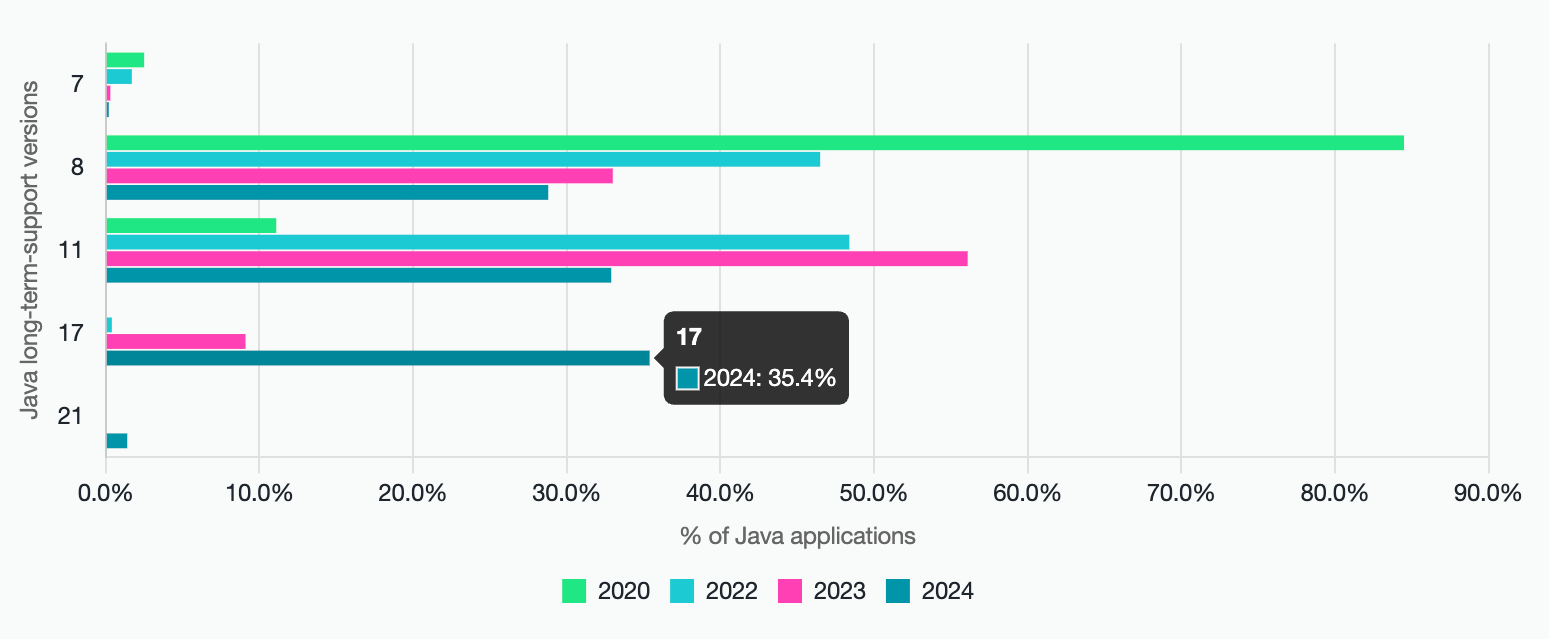
Java 17 是目前 Java 最主流的 LTS 版本,比例已经超越了 Java 8!现在很多新的 Java 开发框架和类库支持的最低 JDK 版本就是 17(比如 AI 开发框架 LangChain4j)。
【实用】Sealed 密封类
在很多 Java 开发者的印象中,一个类要么完全开放继承(任何类都能继承),要么完全禁止继承(final 类)。
其实这样是没办法精确控制继承关系的,在设计 API 或领域模型时可能会遇到问题。
Java 17 将 Sealed 密封类转正,让类的继承关系变得更可控和安全。
比如我可以只允许某几个类继承:
public sealed class Shape
permits Circle, Rectangle, Triangle {
但是,被允许继承的子类必须选择一种继承策略:
1)final:到我为止,不能再继承了
public final class Circle extends Shape {
}
2)sealed:我也要控制谁能继承我
public sealed class Triangle extends Shape
permits RightTriangle {
}
3)non-sealed:我开放继承,任何人都可以继承我
public non-sealed class Rectangle extends Shape {
}
强制声明继承策略是为了 确保设计控制权的完整传递。如果不强制声明,sealed 类精确控制继承的价值就会被破坏,任何人都可以通过继承子类来绕过原始设计的限制。
注意,虽然看起来 non-sealed 打破了这个设计,但这也是设计者的主动选择。如果不需要强制声明,设计者可能会无意中失去控制权。
有了 Sealed 类后,某个接口可能的实现类型就尽在掌握了,可以让 switch 模式匹配变得更加安全:
【了解】新的随机数生成器
Java 17 引入了全新的随机数生成器 API,提供了更优的性能和更多的算法选择:
【了解】强封装 JDK 内部 API
Java 17 进一步强化了对 JDK 内部 API 的封装,一些之前可以通过反射访问的内部类现在完全不可访问,比如:
-
sun.misc.Unsafe
-
com.sun.* 包下的类
-
jdk.internal.* 包下的类
虽然这提高了 JDK 的安全性和稳定性,但可能需要迁移一些依赖内部 API 的老代码。
Java 18
个人感觉 Java 18 提供的功能都没什么用,简单了解一下就好。
【了解】简单 Web 服务器
Java 18 引入了一个简单的 Web 服务器,主要用于开发和测试。
Nginx 不香么,我要用这个东西?
【了解】UTF-8 作为默认字符集
Java 18 将 UTF-8 设为默认字符集,解决了很多字符编码相关的问题,Java 程序在不同平台上的行为会更加一致。
在这之前,Java 使用的是 系统默认字符集,会导致同一段代码在不同操作系统上可能产生完全不同的结果。
【了解】JavaDoc 代码片段
Java 18 引入了 @snippet 标签,可以让 JavaDoc 生成的代码示例更美观,而且支持从外部文件引入代码片段。
不过这年头还有开发者阅读 JavaDoc 么?
Java 19 ~ 20
Java 19 和 20 主要是为一些重大特性做准备,包括虚拟线程、Record 模式、Switch 模式匹配等。
Java 21
Java 21 是鱼皮做新项目时使用的首选 LTS 版本。这个版本发布了很多重要特性,其中最重要的是 Virtual Threads 虚拟线程。
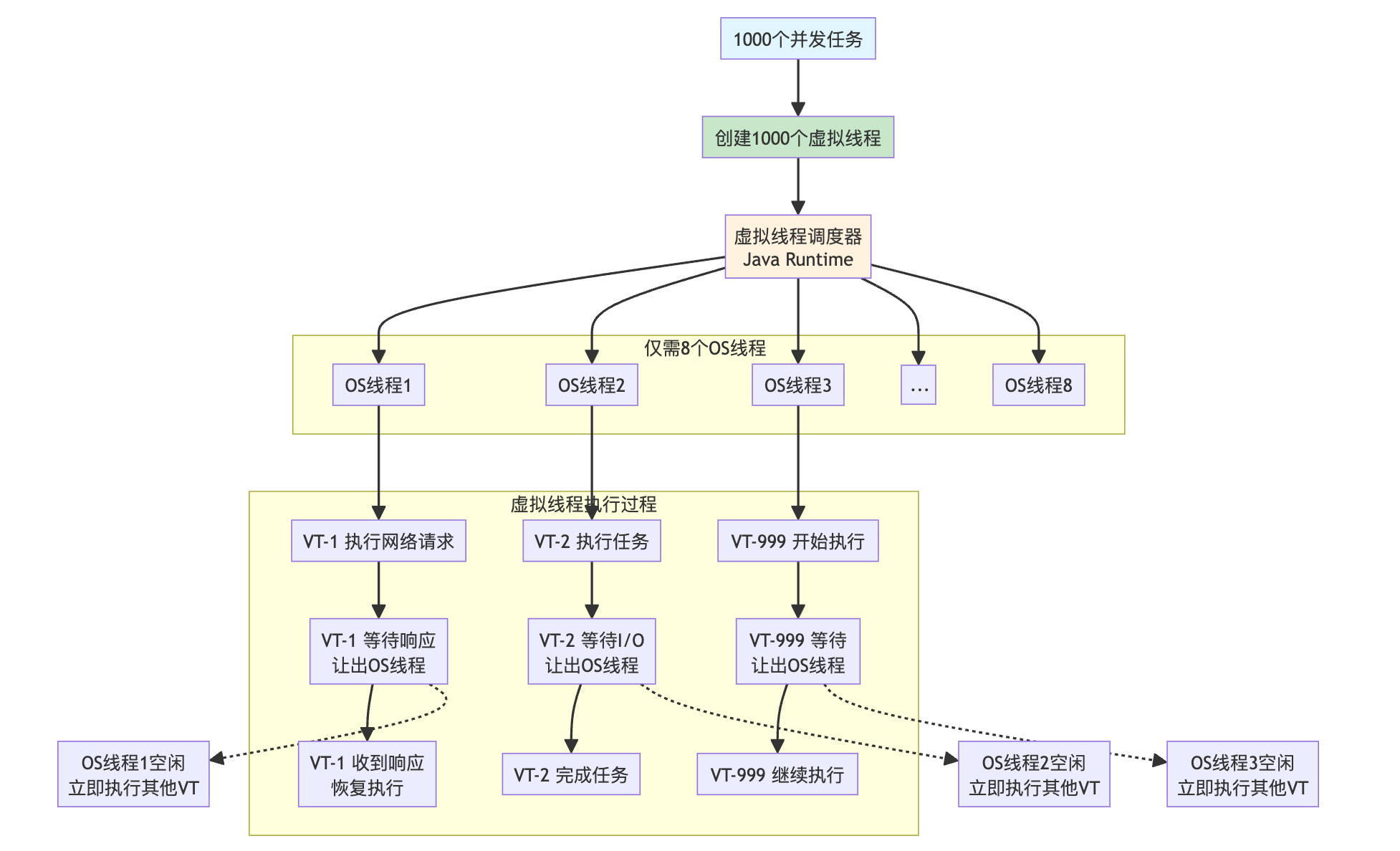
【必备】Virtual Threads 虚拟线程
这是 Java 并发编程的革命性突破,也是很多 Java 开发者选择 21 的理由。
什么是虚拟线程呢?
想象一下,你是一家餐厅的老板。传统的线程就像是餐厅的服务员,假设每个服务员同时只能服务一桌客人。如果有 1000 桌客人,你就需要 1000 个服务员,但这显然不现实。餐厅地方不够,也负担不起那么多员工的工钱。
在传统的 Java 线程模型中也是如此。如果每个线程都对应操作系统的一个真实线程,创建成本很高、内存占用也大。当需要处理大量并发请求时,系统可能很快就会被拖垮。
举个例子,假设开 1000 个线程同时处理网络请求:
public void handleRequests() {
for (int i = 0; i < 1000; i++) {
new Thread(() -> {
创建 1000 个线程会消耗大量系统资源(因为对应 1000 个操作系统线程),而且大部分时间线程都在等待网络响应,很浪费。
而虚拟线程就像是给餐厅引入了一个智能调度系统。服务员不再需要傻傻地等在客人桌边等菜上桌,而是可以在等待的时候去服务其他客人。当某桌的菜准备好了,系统会自动安排一个空闲的服务员去处理。
我们可以开一个虚拟线程执行器执行同样的一批任务,这里我用的执行器会为每个任务生成一个虚拟线程来处理:
public void handleRequestsWithVirtualThreads() {
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
同样是 1000 个,但是 1000 个虚拟线程只需要很少的系统资源(比如映射到 8 个操作系统线程上);而且当虚拟线程等待网络响应时,会让出底层的操作系统线程,操作系统线程就会自动切换去执行其他虚拟线程和任务。
总结一下 Virtual Threads 的核心优势。首先是 超级轻量。一个传统线程可能需要几 MB 的内存,而一个虚拟线程只需要几 KB。你可以轻松创建百万级别的虚拟线程而不用担心系统资源。
其次是 编程简单。你不需要学习复杂的异步编程模式,跟创建一个普通线程的代码类似,一行代码就能提交异步任务。当遇到阻塞的 I/O 操作时,虚拟线程会自动让出底层的操作系统线程。
相关面试题:什么是协程?Java 支持协程吗?
【必备】Switch 模式匹配
Java 14 版本推出了 Switch 表达式,能够一行处理多个条件;Java 21 版本进一步优化了 Switch 的能力,新增了模式匹配特性,能够更轻松地根据对象的类型做不同的处理。
没有 Switch 模式匹配时,我们需要利用 instanceof 匹配类型:
public String processMessage(Object message) {
if (message instanceof String) {
String textMessage = (String) message;
return "文本消息:" + textMessage;
} else if (message instanceof Integer) {
Integer numberMessage = (Integer) message;
return "数字消息:" + numberMessage;
} else if (message instanceof List) {
List<?> listMessage = (List<?>) message;
return "列表消息,包含 " + listMessage.size() + " 个元素";
} else {
return "未知消息类型";
}
}
有了模式匹配,这段代码可以变得很优雅,直接在匹配对象类型的同时声明了变量(跟 instanceof 模式匹配有点像):
public String processMessage(Object message) {
return switch (message) {
case String text -> "文本消息:" + text;
case Integer number -> "数字消息:" + number;
case List<?> list -> "列表消息,包含 " + list.size() + " 个元素";
case null -> "空消息";
default -> "未知消息类型";
};
}
此外,模式匹配还支持 条件判断,让处理逻辑更加精细,相当于在 case ... when ... 中写 if 条件表达式(感觉有点像 SQL 的语法)。
【实用】Record 模式
Record 模式让数据的解构变得更简单直观,可以一次性取出 record 中所有需要的信息。
举个例子,先定义一些简单的 Record:
public record Person(String name, int age) {}
public record Address(String city, String street) {}
public record Employee(Person person, Address address, double salary) {}
使用 Record 模式可以直接解构这些数据,不用一层一层取了:
public String analyzeEmployee(Employee emp) {
return switch (emp) {
这种写法适合追求极致简洁代码的程序员,可以在一行代码中同时完成 类型检查、数据提取 和 条件判断。
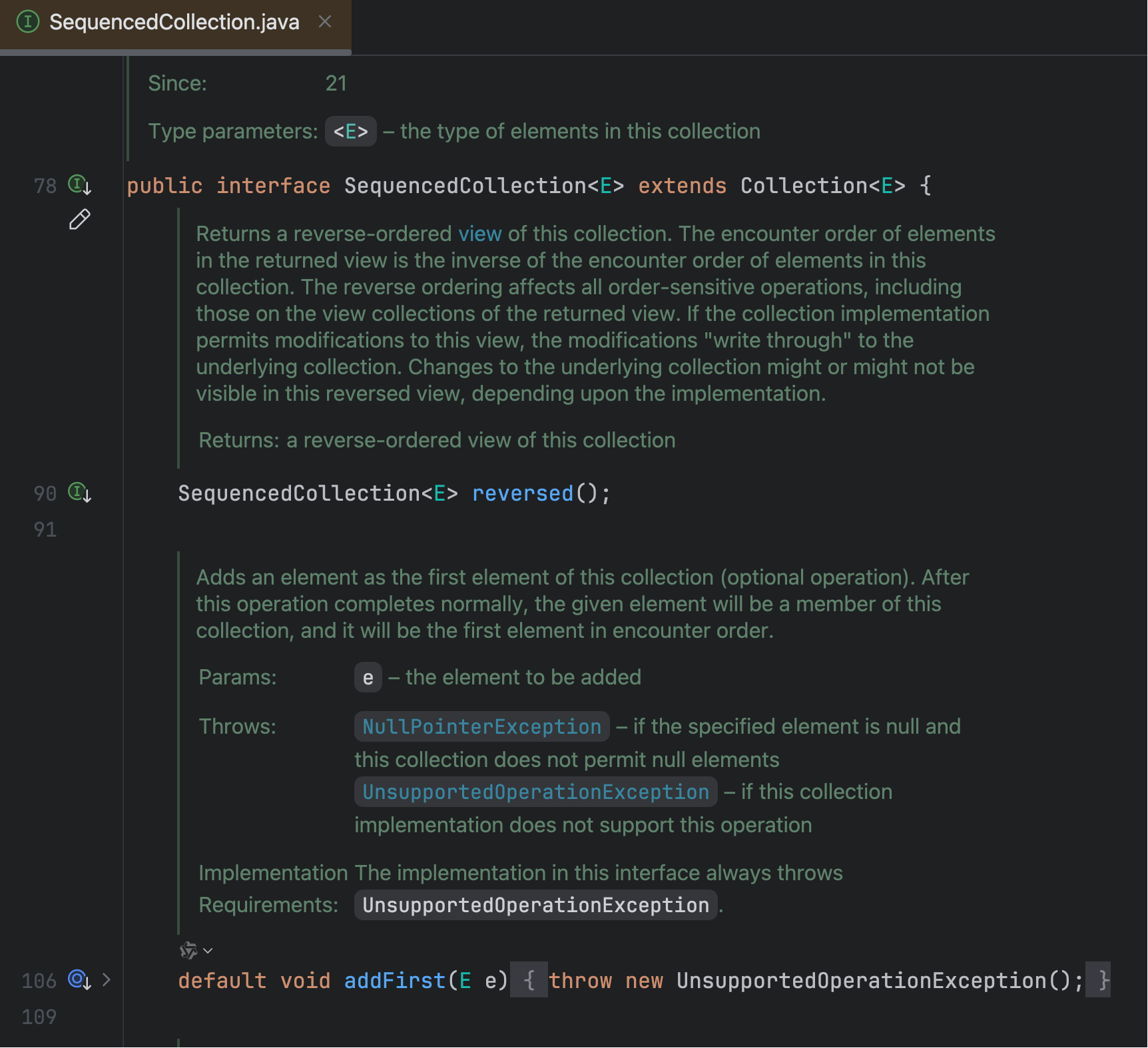
【了解】有序集合
Java 21 的有序集合为我们提供了更直观的方式来操作集合的头尾元素,说白了就是补了几个方法:
List<String> tasks = new ArrayList<>();
tasks.addFirst("鱼皮的任务");
除了 List 之外,SequencedMap 接口(比如 LinkedHashMap)和 SequencedSet 接口(比如 LinkedHashSet)也新增了类似的方法。本质上都是实现了有序集合接口:
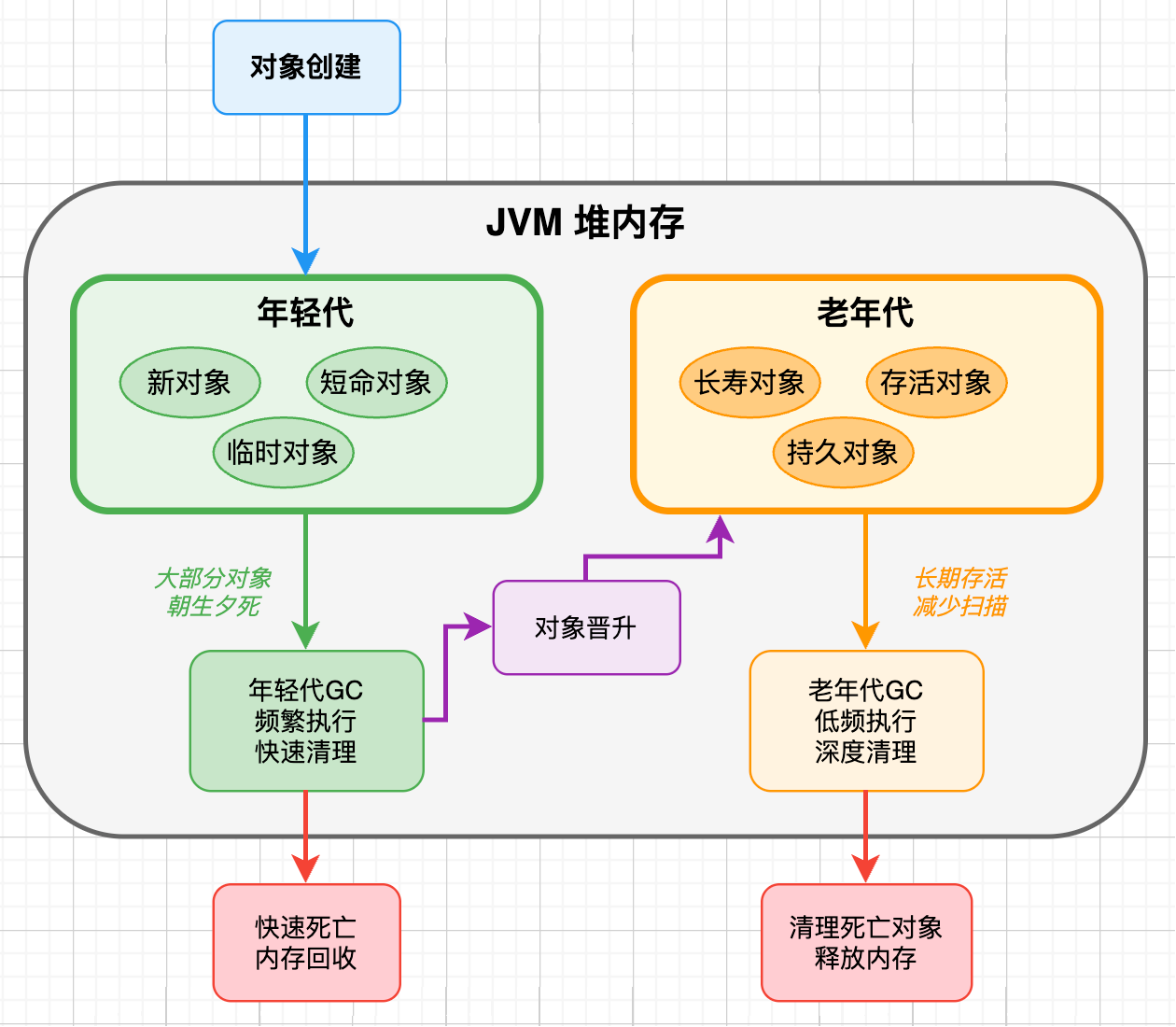
【了解】分代 ZGC
Java 21 中的分代 ZGC 可以说是垃圾收集器领域的一个重大突破。ZGC 从 Java 11 开始就以其超低延迟而闻名,但是它并没有采用分代的设计思路。
在这之前,ZGC 对所有对象一视同仁,无论是刚创建的新对象还是存活了很久的老对象,都使用同样的收集策略。这虽然保证了一致的低延迟,但在内存分配密集的应用中,效率并不是最优的。
分代 ZGC 的核心思想是基于一个现象 —— 大部分对象都是 “朝生夕死” 的。它将堆内存划分为年轻代和老年代两个区域,年轻代的垃圾收集可以更加频繁和高效,因为大部分年轻对象很快就会死亡,收集器可以快速清理掉这些垃圾;而老年代的收集频率相对较低,减少了对长期存活对象的不必要扫描。
Java 22
【了解】外部函数和内存 API
长期以来,Java 程序员想要调用 C/C++ 编写的本地库,只能依赖 JNI(Java Native Interface)。但说实话,JNI 的使用体验并不好,需要手写胶水代码、维护头文件和构建脚本、处理 JNIEnv 和复杂类型转换,一旦接口频繁变更,维护成本较高。
外部函数与内存 API(FFM API)提供了标准化、类型安全的方式来从 Java 直接调用本地代码。FFM API 现在支持几乎所有主流平台,性能相比 JNI 可能有一定提升,特别是在频繁调用本地函数的场景下。
大家不用记忆具体是怎么使用的,只要知道有这个特性就足够了。
【了解】未命名变量和模式
在开发中,我们可能会遇到这样的情况:有些变量我们必须声明,但实际上并不会使用到它们的值。
在这之前,我们只能给这些不使用的变量起一个名字,代码会显得有些多余。举些例子:
try {
processData();
} catch (IOException ignored) {
有了未命名变量特性,可以使用下划线 _ 表示不使用的变量代码,意图更清晰:
try {
processData();
} catch (IOException _) {
Java 23
【了解】ZGC 默认分代模式
Java 22 引入了分代 ZGC,但当时你需要通过特殊的 JVM 参数来启用它:
java -XX:+UseZGC -XX:+UnlockExperimentalVMOptions -XX:+UseGenerationalZGC MyApp
而在 Java 23 中,分代模式成为了 ZGC 的默认行为。
虽然听起来只是个小改动,但这个改变的背后是大量的性能测试和实际应用验证的结果。Oracle 的工程师们发现,分代 ZGC 在绝大多数应用场景中都能带来显著的性能改善,特别是在内存分配密集的应用中,性能提升可能达到数倍之多。
Java 24
【了解】类文件 API
类文件 API 是一个专为框架和工具开发者设计的强大特性。长期以来,如果你想要在运行时动态生成、分析或修改 Java 字节码,就必须依赖像 ASM、Javassist 或者 CGLIB 这样的第三方库。
而且操作字节码需要深入了解底层细节,学习难度很大,我只能借助 AI 来搞定。
有了类文件 API,操作字节码变得简单了一些:
public byte[] generateClass() {
return ClassFile.of().build(ClassDesc.of("com.example.GeneratedClass"), cb -> {
读取和分析现有的类文件也很简单:
public void analyzeClass(byte[] classBytes) {
ClassModel cm = ClassFile.of().parse(classBytes);
System.out.println("类名: " + cm.thisClass().asInternalName());
System.out.println("方法列表:");
for (MethodModel method : cm.methods()) {
System.out.println(" - " + method.methodName().stringValue() +
method.methodType().stringValue());
}
}
第三方字节码库可能需要一段时间才能跟上新特性的变化,而官方的类文件 API 则能够与语言特性同步发布,确保开发者能够使用最新的字节码功能。
【了解】Stream Gatherers 流收集器
Stream API 自 Java 8 引入以来,极大地改变了我们处理集合数据的方式,但是在一些特定的场景中,传统的 Stream 操作就显得力不从心了。Stream Gatherers 正是对 Stream API 的一个重要扩展,它解决了现有 Stream API 在某些复杂数据处理场景中的局限性,补齐了 Stream API 的短板。
如果你想实现一些复杂的数据聚合操作,比如滑动窗口或固定窗口分析,可以直接使用 Java 24 内置的 Gatherers。
还有更多方法,感兴趣的同学可以自己尝试:
除了内置的 Gatherers 外,还可以自定义 Gatherer,举一个最简单的例子 —— 给每个元素添加前缀。先自定义一个 Gatherer:
Gatherer<String, ?, String> addPrefix = Gatherer.ofSequential(
() -> null,
Gatherer.ofSequential 方法会返回 Gatherer 接口的实现类:
然后就可以愉快地使用了:
List<String> names = Arrays.asList("鱼皮", "编程", "导航");
List<String> prefixedNames = names.stream()
.gather(addPrefix)
.collect(Collectors.toList());
System.out.println(prefixedNames);
这个例子展示了 Gatherer 的最基本形态:
虽然这个例子用 map() 也能实现,但它帮助我们理解了 Gatherer 的基本工作机制。
这就是 Stream Gatherers 强大之处,它能够维护复杂的内部状态,并根据业务逻辑灵活地向下游推送结果,让原本需要手动循环的复杂逻辑变得简洁优雅。
Stream Gatherers 的另一个优势是它和现有的 Stream API 完全兼容。你可以在 Stream 管道中的任何位置插入 Gatherer 操作,就像使用 map、filter 或 collect 一样自然,让复杂的数据处理变得既强大又优雅。
OK 以上就是本期内容,学会的话记得点赞三连支持,我们下期见。
更多编程学习资源
-
Java前端程序员必做项目实战教程+毕设网站
-
程序员免费编程学习交流社区(自学必备)
-
程序员保姆级求职写简历指南(找工作必备)
-
程序员免费面试刷题网站工具(找工作必备)
-
最新Java零基础入门学习路线 + Java教程
-
最新Python零基础入门学习路线 + Python教程
-
最新前端零基础入门学习路线 + 前端教程
-
最新数据结构和算法零基础入门学习路线 + 算法教程
-
最新C++零基础入门学习路线、C++教程
-
最新数据库零基础入门学习路线 + 数据库教程
-
最新Redis零基础入门学习路线 + Redis教程
-
最新计算机基础入门学习路线 + 计算机基础教程
-
最新小程序入门学习路线 + 小程序开发教程
-
最新SQL零基础入门学习路线 + SQL教程
-
最新Linux零基础入门学习路线 + Linux教程
-
最新Git/GitHub零基础入门学习路线 + Git教程
-
最新操作系统零基础入门学习路线 + 操作系统教程
-
最新计算机网络零基础入门学习路线 + 计算机网络教程
-
最新设计模式零基础入门学习路线 + 设计模式教程
-
最新软件工程零基础入门学习路线 + 软件工程教程
来源:https://www.cnblogs.com/yupi/p/19075074 |


 發表於 2025-9-5 11:18:00
發表於 2025-9-5 11:18:00